Vorige week ben ik 5 dagen lang naar Leiden getogen voor deGraduate Course “Measuring Science and Research Performance” van het CWTS, hetCentre for Science and Technology Studies van de Unviersiteit leiden.
De dagthema’s waren:
- World of Science, Technology and Innovation
- Research Performance Measurements and Indicators
- Research management perspectives
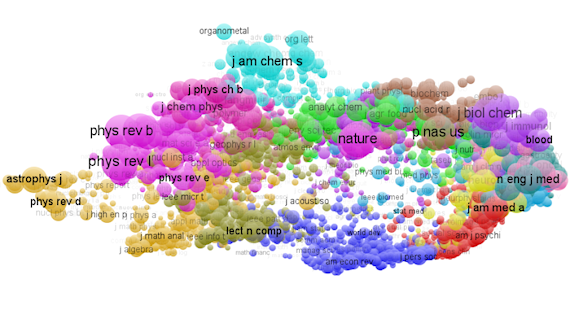
- Science Mapping
- Science Policy Contexts
- Scientometrics 2.0
Hoewel onderdeel van de Universiteits Leiden heeft het
CWTS ook een terugverdienopdracht. Dat bleek soms ook wel bij de uitwijding oversommige toepassingen. Voor hun toekomstige ambitie om ‘Center of Experience’ teworden kan dat een nadeel zijn. Soms was de spagaat tussen het delen vanervaringen en uitwisselen van ideeen enerzijds en het beschermen vancommerciele belangen te sterk aanwezig.
Er was veel aan gedaan het programma gevarieerd en veelzijdig op te zetten en alle aspecten en onderzoeksgebieden van het CWTS kwamen dan ook wel aan bod. Helaas was er minder aandacht voor de methoden voor de cursisten om zelf de aanwezige gegevens te verzamelen en te interpreteren.
Een belangrijke boodschap was dat je de citatiecijfers alszodanig niet zomaar, ongenuanceerd kunt gebruiken, maar dat je die dient af tezetten tegen het algemene prestatiecijfer van het veld.
Ze waarschuwden ook tegen het ‘quick and dirty’ verzamelen en gebruiken van gegevens, maar als het alternatief is om CWTS in te huren heeft dat wel een beetje een toon van eigen belang .
Uiteraard is het zorgvuldig interpreteren, verzamelen en schonen van gegevens belangrijk en uiteraard dienen die cijfers in een geheel met andere indicatoren(ook kwalitatieve) gebruikt te worden. Maar soms geven die quick-and-dirty ggevens toch wel een aardig trend aan.
Wat eigenlijk ook wel steekt is dat alle gegevens die gebruikt worden voor bibliometrische overzichten van 2 grote commerciële firma’s(Thomson Reuters en Elsevier) komen. Dat geeft toch ook een niet zo grootvertrouwen in het geheel.
Zelf worstel ik altijd met de onderwerps-indelingen en dat blijkt ook inderdaad een groot probleem te zijn. Om nog maar te zwijgen van de gemankeerde aandachtvoor humaniora in de cijfergegevens. Wellicht dat het met de komst van de BookCitation Index van WoS beter gaat.
Volgend jaar gaat de cursus aangepast worden, maar duidelijkis wel dat er sprake is van een groeiende belangstelling.
Erg interessant vond ik ook de ingangen tot het waarderen van wetenschappelijke onderzoek in termen van economische groei, innovatie en maatschappelijke waardering.
De cursus werd gegeven in het Willem Einthovengebouw aan de Wassenaarseweg, achter het LUMC. De cursus werd in het Engels gegeven, de medestudenten kwamen uit verschillende landen (NL, SW, FI, DK, FR, IT, AU, ZA,UK).
Al meteen werd duidelijk dat de leszaal in het gebouw te klein was voor het aantal (20) studenten, en door het warme weer werd het wel erg benauwd, gelukkig was er wel veel water voorhanden. Er waren wel voldoende elektriciteitspunten en we kregen allemaal een tijdelijk webaccount, ongeveer de helft had een laptop, er was er een met een iPad en de rest maakte aantekeningen met de hand. Lunch en diner waren goed verzorgd,lunch in het atrium van het gebouw en diner in buffet-restaurant Luxor. Helaas was de koffievoorziening matig, tijdens de lunch en in de – eerste – middag zelfs afwezig.

Als cursusmateriaal kregen we
het boek ‘Citation analysis in research evaluation’van Henk Moed, en dat ga ik komende week eens doorlezen, venals ‘The Publish or Perish Book’ van Anne-Will Harzing (hoorde niet tot eesmateriaal).
Tijdens de cursus en in de ‘suggestions for further reading’ werden nog een aantal leestips gegeven, die ik verzameld heb in een
Endnote-bestand (39 titels) dat beschikbaar is via mijndropbox.