En dan probeer ik een bestand uit Refworks te importeren in Endnote. Dat geeft wel weer de nodige aanpassingen. Uiteindelijk lukt het het beste om het Refworks-bestand te exporteren als 'Tagged Refworks - format'.
Dat geeft wel weer de nodige aanpassingen. Uiteindelijk lukt het het beste om het Refworks-bestand te exporteren als 'Tagged Refworks - format'.
Het aardige van zo'n tagged format is dat je een overzicht van de tags erbij krijgt.
Dan het importeren in Endnote volgens het commando File - Import met als optie Refworks-import.
Ik heb wat User-Defined Fields en die staan in het standaard Refworks-importfilter van Endnote op {IGNORE}. Maar daarom heb ik ze niet gemaakt.
Die User-defined Refworks fields wil ik ingelezen hebben in Custom-fields in Endnote.
Het lastige is dat Endnote erg inconsequent omgaat met de custom-fields. In sommige 'reference types' worden die custom-fields doodleuk gebruikt voor andere veldbenamingen. En dan lukt import niet.
Zaak is dus om eerst in Endnote alle reference types zo aan te passen dat de custom-fields ook Custom 1, Custom 2 etc. heten. Dat doe je via Edit - Preferences - Reference types en dan per stuk Modify Reference Type. Achter de gekozen veldnaam moet dan staan hoe die veldnaam in dat document type moet gaan heten (dus Custom 1 = Custom 1).
Er is wel een optie "Apply to all reference types", maar die werkt niet voor die benamingen die al ingevuld zijn, dus daar heb je niets aan.
De tweede stap is om het import-filter aan te passen. Via Edit - Importfilter kies je het Refworks-Importfilter en maakt eerst een kopie.
Je kiest 'Templates' om de matchende velden te bewerken, en dat doe je weer voor ieder reference type. Gelukkig kun je het ook kopiëren en plakken(Ctrl+C en Ctrl+V).
Dan nog in de Field editing aangeven dat ik in Custom 8 geen kleine letters wil en ik kan alles netjes inlezen.
[In Refworks klikte ik weer per ongeluk op Help en in plaats van een helptekst krijg je dan een akelige herenstem die je probeert iets uit te leggen. O gruwel!
Als je in de rechterzijbalk onder Quick Access iets aanklikt en dan op Help krijg je wel een geschreven helptekst, ze kunnen het dus wel en die engerd is helemaal niet nodig.]
21 dec 2011
Import uit Refworks
9 dec 2011
ICT-termen
Surfmagazine is altijd goed voor een flink aantal nieuwe termen en afkortingen.
In de ICT-wereld gaat het tegenwoordig om IPv6 (de nieuwe generatie internetadressen). Maar het moet behalve snel ook mobiel. Termen als UMTS (telefoonnetwerk met dataverkeer), Wi-Fi (draadloos internet) en LTE (Long term evolution = 4G).
Gelukkig staat Surfnet KPN daarbij terzijde met de overdracht van een aantal IPv4-adressen aan KPN) via RIPE NCC.
In een achtergrondartikel spreekt Surfnet nog over 'consumerization'; 'bottlenecks'en het aanjagen van innovatie'.
Geweldig om te lezen en naar die prachtig sites te surfen en dat op een gewone vrijdagmiddag!
Ook mooi verwoord zijn de nieuwe instellingen voor Surfdiensten waarmee flexibele licenties kunnen worden afgesloten “LMNG speelt in op trends als SaaS en cloud computing”.
Waarbij LMNG staat voor Licentiemodellen Next Generation en SaaS voor Software as a Service. Maar dat laaste begrip is al een tijd langer in omloop. Cloud computing komt weer terug in de column van Jan Bogerd “De cloud dringt binnen” over de constatering dat docenten en studenten steeds vaker gebruik maken van Google Apps en diensten als Dropbox.
Dropbox propageer ik zelf ook, erg handig zo’n share op internet, terwijl ik merk dat de meeste medewerkers er niet mee bekend zijn.
Met Google Apps, niet de individuele maar de zakelijke i.c. educatieve toepassing hebben we binnen KNAW-verband ge-experimenteerd. Je kunt dan inderdaad ook bestanden delen.
Een stapje verder nog gaat het ‘Unified Communications’ programma. UC staat voor e-mail, instant messaging, telefonie en videoconferencing in een. Eigenlijk betekent het het stringent bijhouden van je agenda zodat je optimaal daarvan gebruik kunt maken, m.n. voor HNW (Het Nieuwe werken).
Microsoft heeft een infrastructuur (zonder telefooncentrale) draaiend op Microsoft Office Communications Server, die zal worden opgevolgd door Lync. Bij Surfnet valt het onder 'samenwerkingsinfrastructuur'.
Dat gaat in onze – traditionele – werken-omgeving nog wel lastig worden, daar zelfs het bijhouden van een agenda in Outlook al als moeilijk wordt ervaren, terwijl “het bijhouden van de agenda cruciaal is voor het succes van UC “
5 dec 2011
Metis 2011

Metis is het onderzoeksregistratiesysteem [ofwel een CRIS (= Current Research Information System)]van de universiteiten. Het is ontwikkeld door het Universitair Centrum voor Informatievoorziening van de Radboud Universiteit in Nijmegen en wordt door alle universiteiten gebruikt. Metis is een Oracle databasesysteem dat functioneert samen met Macromedia Coldfusion. En is via Internet te gebruiken. Zie ook de Metis guide (handleiding) en demo (2006).
In oktober 2007 heb ik mijn eerste stukje over Metis geschreven en ik zie nu dat er al veel veranderd is sinds die tijd. Links die niet meer werken, maar ook hele modules en systemen die veranderd zijn. Zo is de Consultatie-module van Metis (de toegangen tot de verschillende Metis-systemen per universiteit) uit de lucht genomen en Dare, het repository-project is nu omgevormd tot NARCIS. In Narcis kun je nog wel een overzicht van de aangesloten repositories vinden. Maar of die allemaal Metis gebruiken weet ik niet.
Metis wordt door de KNAW en ook door andere universiteiten gebruikt als managementinformatiesysteem over de uitkomsten van onderzoek enerzijds en anderzijds als toegangspoort tot de repository. Voor de repository zelf wordt weer aparte software gebruikt.
Het idee van Metis is dat alle onderzoeksinstellingen op uniforme wijze de inzet en de uitkomsten van het onderzoek kunnen rapporteren (aan ministerie). Het gaat dan om cijfers: met zoveel fte personeel kunnen zoveel publicaties, zoveel lezingen, zoveel bezoeken en zoveel overige functies bekleedt worden. Dit alles volgens de definities van het SEP, het standaard evaluatie protocol.
In 2008 heb ik een blogpost over SEP geschreven. Zover ik weet werken nog alle universiteiten met SEP en worden ze eens in de 4-6 jaar gevalueerd aan de hand van SEP. Zie ook de bijgewerkte brochure over het Nederlandse wetenschapssysteem van het ministerie.
Er gaan wel stemmen op om meer te doen aan ´valorisatie´, daar is ook het evaluatievoorstel EriC opgebaseerd, maar echt operationeel is dat (nog) niet. Ook de VSNU heeft op de website wat informatie over valorisatie.
De VSNU heeft ook een aantal definitie-afspraken beschreven, die gehanteert kunnen worden bij het bepalen van de soort gegevens waarop geraportteerd moet worden. De UB van de Universiteit van Maastricht heeft een overzicht gepubliceerd over de Metis-resultaattypen en de relatie met de VSNU-SEP definities.
Metis werkt volgens het datamodel van EuroCris (Cerif)
” Gradually the need for a standard format for interchange of R&D information was seen. The European Commission put together a group of experts nominated by national governments with the purpose to define a Common European Research Information Format (CERIF).”
Op de site van EuroCris is meer informatie over de geschiedenis van CRIS en van dit Cerif-formaat.
Niet alleen Metis werkt op basis van dit Cerif-datamodel ook andere CRIS software, zoals Pure (Deens) en Converis (wordt gebruikt door LUMC e.a. medische universiteiten).
Dus het begint bij de SEP, dat schrijft voor dat de onderzoeksinstellingen moeten rapporteren over wat ze presteren. In de praktijk gaat het over de aantallen: aantallen publicaties, aantal dissertaties , aantal congressen, aantal andere activiteiten.
Die prestaties=activiteiten kunnen per persoon worden geregistreerd in Metis. Metis heeft daartoe een module – Personal Metis – waar een onderzoeker zelf zijn eigen activiteiten : publicaties etc. kan registreren. De onderzoeker heeft een uitgebreide lijst van zogenoemde resultaattypen = soorten activiteiten = waarop hij kan rapporteren. Voor het NIOO hebben we er nu zo’n 20 op een lijstje varierend van “wetenschappelijk tijdschriftartikel” – via “niet wetenschappelijk boekhoofdstuk” en “invited speaker” tot “patent”.
Die jaarlijkse rapportages gebruiken we voor het interne jaarverslag – het Business Report – en voor de cijfermatige rapportage aan de KNAW (die op zijn beurt weer rapporteert aan het ministerie). 

Metis heeft naast een Personal Metis per onderzoeker een algemene Data Entry & Control Module, bedoeld voor de institutioneel beheerders.
Met deze beheermodule kan ik als beheerder correcties doorvoeren en namen van medewerkers toevoegen en of aanpassen en daarmee ook accounts beheren. 
In een diagram geeft de ontwerper aan hoe het Metis-systeem in elkaar zit en onderling verbonden is. Daarbij zijn de begrippen belangrijk als werkrelatie (hoe is een auteur verbonden methet instituut), onderzoeksactiviteit en onderzoeksbijdrage (bijv. projecten, maar kan ook afdelingscoderingen), organisatieonderdeel (afdeling) en resultaten (resultaattypen, soorten activiteiten).
Het vereist wele en heel ander jargon voor je een beetje vlot met het systeem kunt omgaan. Er zijn ook verschillende soorten classificaties die je kunt gebruiken: VSNU-classificatie, resultaattypen-classificatie en een interne classificatie. Dat maakt het soms erg verwarrend. 
Vanuit de beheermodule is het mogelijk om een aantal overzichten te maken m.b.v. verschillende filters. Helaas is het systeem toch een tikje te star om echt mooie overzichten te genereren. We gebruiken de publicatielijsten uit Metis nu wel om – dynamisch – overzichten op onze website te publiceren. Bij iedere publicatie die wordt toegevoegd worden de publicatielijsten op de website aangepast. Dat werkt nu wel heel mooi.
Ook kun je importeren uit Endnote en exporteren naar RIS-formaat. Op dit moment wordt onderzocht of er ook rechtstreeks vanuit Web of Science kan worden geimporteerd.
De KNAW heeft een koppeling tot stand gebracht tussen Metis en de software Eprints. Met Eprints runnen we onze repository. Vanuit Metis kunnen wij, en via Personal Metis kan de onderzoeker zelf ook, de full text van zijn publicatie uploaden en ter beschikking stellen. Uiteraard alleen indien dat is geoorloofd (Open Access).
De metadata voor de full text komt dus uit Metis en wordt in Eprints gekoppeld aan de pdf. We proberen nu ook de ‘green road’ operationeel te krijgen, d.w.z. dat onderzoekers hun definitieve auteursversie (die al is gepeerreviewed, maar nog niet gelayout) kunnen uploaden naar de repository. De publicaties zijn dan onmiddellijk voor eidereen toegankelijk.
De publicaties in de repository worden door Narcis geharvest en op die manier zijn ze te vinden in het overzicht van de Nederlandse wetenschappelijke literatuur.
Omdat het Metis-systeem een jaren negentig software-architectuur kent, waarbij ook nog eens vanuit verschillende kanten input aan gegeven is, wordt het tijd om een ander systeem te gaan gebruiken. Daartoe is de MetisGebruikersgroep overgegaan tot het opstellen van een programma van eisen en een plan van aanpak. Marc Dupuis beschrijft in de Newsletter van de Association for Learning Technology wat er speelt bij de aanbestedings van zo’n nieuw onderzoeksinformatiesysteem, ofwel een CRIS (= Current Research Information System).
Het ziet er evenwel naar uit dat we voorlopig nog wel met Metis blijven werken.
21 nov 2011
Bijeenkomst NVB
Vorig jaar en het jaar daarvoor kon ik drie thema’s onderscheiden bij het jaarcongres van de NVB, vereniging van informatieprofessionals:
- ordening versus serendipity
- sociale media en verwording maatschappij
- imago informatieprofessional
Over serendipity heb ik niets gehoord en de discussie rond het vermeende gevaar van sociale media lijkt ook verstomd, want zelfs de NVB heeft zich verbonden met de Nederlandse Social Media Academie.
Dit jaar was “Een ander vak” nadrukkelijk het centrale thema van het congres.
Veel heb ik over ‘het vak’ niet gehoord behalve (en dan kan ik mijn eigen verslag van 2010 weer citeren):
“Ons vak is een ander vak geworden vlgs Wesseling. Daar ben ik het niet mee eens. De vorm en media zijn anders geworden, de omgeving is sterk verandert door de toepassingen van de moderne technologie en de veranderende maatschappij, maar de essentie is hetzelfde gebleven = toegang geven/faciliteren tot informatie.
Natuurlijk moet je als informatieprofessional, maar in welk vak niet, meegaan met je tijd en gebruik maken van nieuwe mogelijkheden, zo ook van de mogelijkheden die de sociale media bieden. “
De track “Het vak: Opleidingen onder de loep: wat moet er gebeuren om ‘het vak’ aan te passen aan de eisen van deze tijd?” heb ik niet gevolgd. Van Anneke Dirkx die die track wel volgde hoord ik de kreet KID-manager (kennis – info – data). Zij suggereerde ook dat de NVB meer zou moeten doen aan IP-branding, en daar ben ik het wel mee eens.
Overigens hoorde ik uit de Track “Happe.ning Bibliotheek 2.0” nog de kreet ‘embedded librarian’ , van Bert Huizing - waarschijnlijk overgenomen van de ‘clinical librarian’ maar dan ook voor andere dan medische omgevingen. Maar ook die track heb ik niet gevolgd.
Dat een sterkere ´branding´van het vak Informatie Professional noodzakelijk is bleek ook uit het plenaire debat, dat gevoerd werd door Marleen Stikker van Waag Society , Geert Loving(Institute of Network Cultures) en Stine Jensen (auteur) onder leiding van Pieter-Jan Hagens. Geen van deze vier personen had blijkbaar een duidelijk beeld van de doelgroep waarvoor zij optraden. Dat leidde tot een tamelijk gratuit debatje over zoeken en de macht van Google. Een dappere deelnemer uit de zaal probeerde het tij te keren, maar werd door een verkeerde woordkeuze (hyvesvrouwen) min of meer weggehoond.
Overigens had Marleen Stikker in haar 10-minuten praatje het over ‘open data’ en de motieven daarvoor: democratie, efficiency, innovatie, leefklimaat. Het zou open by default moeten zijn. Marleen referereert aan appsvoornederland.nl waarmee de overheid open data aan de burgers wil brengen. Toch wel interessant. 2 van de panelleden hebben De Digitale Stad als achtergrond. Omdat ik dat als dds-bewoner van het eerste uur interessanter vond dan debat heb ik wat rond zitten neuzen naar de geschiedenis van DDS en vond een aardig achtergrondartikel.
Er hadden zich 1100 mensen ingeschreven voor het congres en op de deelnemerslijst (die ik overigens niet van de organisatie, maar onderhands heb ontvangen) kon ik zien dat ze bijna allemaal een werkgever hebben. De crisis lijkt wat dat betreft toch niet zo erg. Ook tijdens de ochtendkoffie kreeg ik een beeld van een tamelijk stevige positie van de bibliotheek: in een ziekenhuis zijn de arts-assistenten verplicht om een CAT (Critical Appraised Topic) op te stellen Een CAT probeert zich toe te spitsen op één duidelijk geformuleerde, liefst enkelvoudige vraag en vervolgens wordt geprobeerd om aan de hand van de literatuur daar een evidence based antwoord op te vinden. De rol van de bibliotheek is daarbij van cruciaal belang(ook een ‘embedded’soort werk).
Na de pauze heb ik de Track `Web 3.0`gevolgd over het semantisch web en linked open data. Vaag herinnerde ik me dat ik ooit met bewondering een presentatie heb bijgewoond, waarbij ook het Semantisch Web ter sprake kwam. Tijdens het congres kon ik het me niet meer herinneren, maar na wat pogingen weet ik het weer. Het was in september 2004 tijdens het EAHIL congres in Santander. Daar sprak Les Grivell, destijds van EMBL ( European Molecular Biology Organization’ over ´Fingerprinting metadata´. Of om de hele titel te citeren `Conceptual fingerprinting as both a literature discovery tool and a means of semantic interlinkage of bibliographic, sequence and image databases`. Er was ook een Continuing Education Course over RDF en Semantic web van Benoit Thirion en Ioana Robu ‘Structuring the information on the Internet: the Dublin Core metadata, RDF and the Semantic Web’. In het archief van BIOMEDCentral is ook nog een interview met Les Grivell te lezen over het ‘fingerprinting the literature’. Les Grivell was destijds projectleider van het E-BioSci project, dat in 2005 is afgesloten en waaruit nog steeds CiteXplore Literature searching bestaat: een andere manier van (biomedische) literatuurzoeken. Ik meen dat hij destijds gebruik maakte van Collexis software, inmiddels door Elsevier overgenomen.
Kortom, Web 3.0-semantisch web is voor mij niet zo nieuw als het wellicht op het eerste gezicht aandoet. En niet alleen voor mij, bleek, maar voor het merendeel van de aanwezigen. Daarop had Ivo Zandhuis, die de discussies leidde zich verkeken, want hij had een langzame introductie bedacht, die helaas uitliep op een wat moeizame start en daarna, helaas voor track-switchers, een omgooien van het programma.
Edgar Meij geeft een helder verslag van zijn onderzoek naar ‘Semantic Search’: de ontwikkelingen in de information retrieval. Hij is vorig jaar daarop gepromoveerd aan de UvA “Combining Concepts and Language Models for Information Access” en blogt erover op zijn website.
Hij laat zien hoe het zoeken veranderd is, en hoe de problemen die op dit moment spelen niet zozeer computationeel van aard zijn. Het gaat er meer om te proberen te begrijpen/modelleren van de emnselijke cognitie en zo een dieper begrip te krijgen voor queries en content. Hoe hangen de zaken met elkaar samen. Wat kun je als zoekmachine uit de semantiek van de zoekvragen halen, wat niet letterlijk in de bewoordingen staat: ‘het nieuwe zoeken’ maakt gebruik van aggregatie, analyse en voorspellingen, semantische profielen, semantische queries & log analyse, en meer complexere taken.
Combinatie van document-zoeken en data-zoeken met behulp van een zoekparadigma dat structuur/semantiek gebruikt om de intentie van de gebruiker weer te geven.
- Leuke termen: Begrijpen van queries ‘snap to grid’ en interface en interactie: adaptief of met ‘rich snippets’. Semantisch web = delen van data in de vorm van linked data en rda.
Uit een onderzoek naar RDFa,(or Resource Description Framework – in – attributes) blijkt dat al eenderde van alle webpagina’s metadata in RDFa heeft, zoals de Open Graph protocol van Facebook = like
rNews standaard datamodel voor semantisch markup van nieuws sites RDFa. Schema.org =gestandaardizeerde RDFa van zoekmachines
DHZ: fietstas-project tekst-analyse op basis van ANP-berichten: kennisbeheer en kennisindeling – thesaurus structuur (die moet ik nog eens nakijken).
Wat mij betreft was Edgar Meij de held van de dag!
De track Web 3.0 had verder nog 2 praktische presentaties: Lukas Koster van UvA over de verrijking van de catalogus met linked open data.
Linked Data gaat over het verbinden van onderdelen met elkaar over het web, d.m.v. URI’s(Uniform Resource Identifiers) en de triples (subject, predicaat, object) volgens een standaard RDF (Resource Description Framework). Lukas gaat in op de geschiedenis, Tim Berners-Lee in een TED-lezing in 2009 en Dbpedia (de beruchte wolk –linked open data cloud). Voor het eerst heb ik van linked data gehoord op 11 december 2009 tijdens de SURF-bijeenkomst Advanced Services for Researchers van Frank van Harmelen en daarna nogmaals tijdens de Emtacl in Trondheim.
Het aardige van de presentatie van Lukas is dat hij probeerde het heel praktisch te houden, door in te gaan hoe je in de praktijk bijv. links zou kunnen leggen in de catalogus naar andere stukjes informatie over hetzelfde onderwerp. Zijn presentatie is te lezen op Slideshare, waar ook zijn duidelijke uitleg over de principes van linked data staan. Hij maakt gebruik van de standaard van Bibliographic Ontology Specification voor het bibliografisch beschrijven van referenties voor het semantisch web.
Een van de linked data opties is om het traditioneel catalogiseren te verrijken met andere FRBR-expressies en manifestaties. De FRBR (Functional Requirements for Bibliographic Records) is het entiteiten-relatiemodel voor titelschrijvingen van de IFLA uit 1998. 
Wat is er nodig om wereldwijd gebruik te kunnen maken van Linked Cataloguing?:
- Wereldwijd gedeelde metadat opslag(plaatsen)
- Mondiale autorisatie bestanden (namen bijv.)
- Open catalogiseersystemen
- Linken met URIs moet worden ondersteund
Lukas heeft een proefproject gedaan met het Theater Instituut, waarbij allerlei gegevensover theaterproducties uit verschillende bronnen gelinkt worden. De problemen die ze daarbij tegenkwamen hadden vrnl. betrekking op het niet-uitwisselbare formaat van de opgeslagen gegevens (verschillende catalogussystemen, geen centrale ‘work’ beschrijving, maar alleen specifieke ‘manifestaties’ en problemen met matchen van tekst en copyright.)
Wat er nodig is is dat bibliotheken hun gegevens als open data publiceren en dat bibliotheeksystemen op een uitwisselbare manier hun gegevens opslaan.
Het kenniscentrum Digitaal Erfgoed Nederland publiceert een handleiding over het publiceren van open linked data.
Voorlopig adviseert Lukas af te wachten wat voor keuze de Library of Congress gaat maken nu zij besloten hebben af te stappen van Marc en over te gaan op linked data.
Dan is het de beurt aan IDM studenten van Klaas Jan Mollema met een presentatie van een project met gegevens van NCB Naturalis.
De studenten hebben een database gebouwd in RNAToolset m.b.v. Darwin Core metadata en onderdelen gelinkt met andere databases. Ze hebben daarvoor gebruik gemaakt van Trezorix software. Trezorix is een verzelfstandiging van de automatiseringsafdeling van Naturalis. Ze hebben veel tijd besteeed aan het maken van indelingen en het (handmatig) converteren van Excel-bestanden. De toegevoegde waarde hiervan is me niet geheel duidelijk. Wat ze hebben laten zien had m.i. ook een normale MS Access database kunnen zijn.
Schattig is wel dat ze zeiden dat ze zich IT-ers voelden. Duidelijk is wel dat er nog wat geleerd moet worden, ook als ze uiteindelijk toch IP-ers worden:)
Alles bij elkaar was het weer een leuke en leerzame bijeenkomst. Veel mensen gesproken en in een goede sfeer samen gezeten. Jammer is wel dat van het IP-branding nog niet veel terecht komt. Van de tijdens het jaarcongres 2009 aangekondigde Taskforce (TACIS, Taskforce Arberidsmarktcampagne Informatiespecialisten)heb ik ook nooit meer wat vernomen. Daar ligt toch nog een taak.
Tevreden terug op de fiets naar mijn Wageningse appartement.
16 nov 2011
Gelezen in 2009/2010
Overzicht van mijn 'gelezen' lijst voor 2009 en 2010: (voor 2008 zie voorgaand verslag)
**
Lanting, Menno. Connect!: de impact van sociale netwerken op organisaties en leiderschap. Amsterdam [etc.]: Business Contact, 2010.
**
*Chris Anderson .Free: The long tail: Hoe het nieuwe Gratis de markt radicaal verandert . Nieuw Amsterdam, 2009. http://lifehacking.nl/algemeen/free-artikel/ (Gratis e-book)
**
*Darwin, Charles, and Fieke Lakmaker. De autobiografie van Charles Darwin, 1809-1882: de oorspronkelijke versie. Amsterdam: Nieuwezijds, 2008.
Nuchter en helder geschreven overzicht van zijn leven en werk. Zie mijn logje met opmerkelijke uitspraken.
**
* Volledig communicatiegeorienteerde informatiemodellering FCO-IM, met bijbehorende case-tool. / door Guido Bakema, Jan Pieter Zwart en Harm van der Lek. Academic Service, 2005. ISBN 9039524181
FCO-IM is de facto standaard voor databaseontwerp.FCO-IM staat voor Fully Communication Oriented Information Modelling. Dit is een leerboek met opdrachten, voorbeelden en tips. FCO-IM is opvolger van NIAM (Natuurlijke taal Informatie Analyse Methode). Ook de FCO-Im -informatiegrammatica maakt gebruik van natuurlijke taal zinnen. Het classificeren (indelen in groepen) en kwalificeren (betekenisvolle naamgeving) moet identificeerbare en redundantievrije objectbeschrijvingen opleveren. In het Informatiegrammaticadiagram worden de verschillende tyoen in hun onderlinge samenhang getoond. Het gaat om feittypen, labeltypen, objecttypen, feittypeexpressies en objecttype-expressies. Hoewel op het eerste gezicht sommige begrippen wat moeilijk overkomen is het geheel helder uiteengezet.
**
* Budd, J. (2008). Self-examination: The present and future of librarianship. Westport, Conn: Libraries Unlimited.
John Budd schrijft in een lange monoloog zijn visie op de wereld, waarbij ook bibliotheken aan bod komen. Op de achterflap staat : "Through intellectually rich and engaging entrees into ethics, democracy, social responsability, governance and globalization ..."e ja, die onderwerpen zijn allemaal voorbijgekomen in dit 281 pagina's tellende boekwerk. Als hij de 7 hoofdstukken ieder in 2 Aviertjes had weten te pakken was hij wat mij betreft"een 'Meister' geweest. Nu is het voornamelijk gefilosofeer en offshow van wat hij allemaal kan citeren. De toekomst van de bibliotheek ben ik er niet tegengekomen.
**
* De draagbare lichtheid van het bestaan: het alledaagse gezicht van de informatiesamenleving / onder red. van Valerie Frissen en Jos de Mul. Kampen, Uitgeverij Klement, 2008. ISBN 9789086870301
Bundel essays, van een aantal, jonge, onderzoekers die berichten over de relatie technologie en samenleving. Uitgangspunt is dat dagelijkse, triviale en soms onvoorspelbare praktijken van de gebruikers de loop van de technologie en de vorm van de informatiesamenleving bepalen. Het gaat over de 'bricoleurs'i.t.t. íngenieurs', een antropologische benadering van triviale telefoongesprekken, ambient intelligence, de technologische toekomstvisie en de emancipatie van de gebruiker. Gadgets maken het leven misschien niet draaglijker, maar zeker wel draagbaarder, is de slotconclusie.
**
* De snavel van de vink: evolutie op heterdaad betrapt / door Jonathan Weiner. Contact, 1994. ISBN 90 25406157. Vert. van The beak of the finch: a story of evolution in our time.
Uitleg over het voortgaande proces van natuurlijke selectie. Met als voorbeeld de evolutionaire aanpassing van Darwin-vinken op de Galapagoseilanden, wordt helder uitgelegd wat evolutie is.
**
* Het nieuwe werken: op weg naar een productieve kenniseconomie / door Dik Bijl. Den Haag, Academic Service, 2007. ICT bibliotheek. ISBN 9789012119481
Het nieuwe werken, een door Microsoft in 2005 beschreven concept voor verhoging vasn de productiviteit van de individuele kenniswerker. Uitgaande van de factor 4 index met als hoofdcategorieen technologie, organisatie, cultuur en inspiratie wordt de werknemer persoonlijk aangesproken op zijn werkhouding. Werkplek aanpassing, flexplekken en werken kan overal, en werktijd aanpassing, geen 9-5, maar altijd en overal tussendoor. Boekje leest lekker weg.
**
* Iedereen : hoe digitale netwerken onze contacten, samenwerking en organsiaties veranderen. / door Clay Shirky. Business Contact, 2008 ISBN 9789047000808. Vert van 'Here comes everybody'
Gemakkelijk leesbaar boek over de sociaal-psychologische veranderingen, die mogelijk zijn geworden door toepassing van Internetapplicaties.
Bijeenkomst 11 november van het Onderzoeksdataforum
Het Surfshare programma eindigt dit en zal worden afgesloten met de SURF Onderzoeksdag op 9 februari 2012 in Media Plaza in Utrecht.
“Met het SURFshare-programma wil SURFoundation een gemeenschappelijke infrastructuur realiseren die de toegankelijkheid èn de uitwisseling van onderzoeksinformatie bevordert.”
Maar het Onderzoeksdataforum blijft bestaan.
Deze bijeenkomst zal worden besteedt aan 2 nieuwe rapporten: het Witboek dataprofessionals en de rapportage Podium Plus.
Daarna zal Bram van de Werf dieper ingaan op metadata.
De werkgroep Datastewardship van het Onderzoeksdataforum (waar ik zelf deel van heb uitgemaakt) heeft een witboek geschreven over het beroep dataprofessional. De werkgroep doet verschillende aanbevelingen in het Witboek Dataprofessionals in Nederland. Rob Grim voorzitter van de werkgroep geeft een nadere toelichting op het Witboek en neemt de aanbevelingen door.
Het Witboek Dataprofessionals geeft een overzicht van de datamanagement-ondersteuning bij 3 onderzoeksinstellingen NIOO, TUD, UvT
Rob geeft in het kort zijn impressie over de drie organisaties:
NIOO: afspraken over workflow – kwaliteit van dataverzameling – koppeling publicaties
TUD: permanente toegankelijkheid – veel DIY – registratie ws output
UvT: ondersteuning domein experts – lokaal naar centraal – geen opslag cultuur
De werkgroep is in 2009 gestart met het opstellen van “terms of reference:: een afbakening tot het profiel/ de competenties van ondersteuners van onderzoekers
Er wordt ingegaan op de rol van de dataprofessional in drie fasen van onderzoek: voorbereiding, uitvoering, evaluatie.
De aanpak is een literatuuronderzoek, gevolgd door een case studie bij ieder van de drie deelnemende instellingen d.m.v. interviews met onderzoekers, om te kunnen beschrijven wat de algemene knelpunten zijn en wat voor ondersteuning zij nodig hebben.
Datamanagement onderscheiden we in drie groepen: data-archivering, metadata, digitale duurzaamheid.
Uit literatuur komen vier belangrijke vaardigheden voor dataprofessional naar voren: data-archivering, softskills, kennis van wetenschappelijk onderzoek(smethoden), ict-skills.
- Rob verwijst hier ook naar de presentatie van Youngseek Kim tijdens de 6th International Data Curation Day over ‘Education for eScience professionals”.
Overigens ook aardig om te lezen is de masterscriptie De Datalibrarian in Nederland van J. Puttenstein, die in algemene zin schets hoe de situatie bij de Nederlandse Universiteiten is.-
Wat zijn de aanbevelingen:
Er moet training en opleiding worden aangeboden, niet alleen voor ondersteuners, maar ook voor onderzoekers zelf, specifiek maar ook een algemene basis voor alle wetenschappen.
Verder kan gekeken worden naar: UFO-profielen, GO-opleidingen, op maat trainingen, docenten, bijv. in overleg met eScience center.
Vervolgens kwam Paulien Wiersma over project PodiumPlus mogelijkheden tot data-opslag mbv Dataverse
Ervaringen met open source programma Dataverse (Harvard) en ervaringen met samenwerking met andere universiteiten. Er is nu een officiële dienst van Universiteit Utrecht, hosting bij Vancis (Sara dochter), en is nu een openbaar netwerk.
De metadata wordt geharvest door Harvard DataVerse: met federatieve inlog. Het is bedoeld voor middellange termijn opslag met koppeling naar DANS via SWORD protocol.
In het project heeft Paulien de licentievoorwaarden Dataverse vergeleken met DANS en 3TUD, en ook een vergelijking van de metadata en formaten.
Bijvoorbeeld nu vanwege de NWO-verplichting om data op te slaan daardoor komen er toch meer mensen naar DVN. Zie het als voorportaal., lokale variant van Harvard DataVerse
Grote machine gegenereerde data past er niet in, maar het werkt snel: onderzoekers krijgen meteen een URL – persistente handle.
Na de thee geeft Bram van de Werf een presentatie over ‘Metadata en sustainability”. Bram is directeur van Open Planets Foundation over metadata en duurzaamheid bij lange termijn opslag van onderzoeksgegevens. Voorheen bemoeide hij zich met Europeana. Europeana heeft ook een Toughtlab waarin ze een aantal tools voor het verrijken van metadata tonen Europeana is oorspronkelijk ook bedoeld als metadata-project.
Ipv preservation praten over lange termijn toegang.
Er is te snel overgestapt op het omzetten – normaliseren – van data- bits. Daar is niet genoeg over nagedacht, aldus Bram. Metadataschema’s zijn niet zo belangrijk als er maar over nagedacht is en het kan interopereren met anderen. Hoe beter de metadata hoe beter de objecten gebruik gaan worden”.
Met de community onderzoeken van de technische metadata, niet bij ingest (want dan creëer je een bottleneck), maar maak een enrichment layer in je repository en gebruik/ontwikkel tools om de metadata daar te verrijken. vd Werf ziet veel in het verrijken van de metadata door in de repository de hiaten in de technische metadata op te sporen
Gebruik is de sleutel, kijk naar de requirements en use cases, die gebruikt kunnen worden voor data mining en data modelling
Het Planets project, waaruit de Open Planets Foundation voorkomt had als ambitie het opzetten comptetentiecentrum waaruit de lidstaten dan kunnen putten (voor diensten en expertise).
Tijdens de discussie aan het slot van de middag bleek de centrale vraag “ Wat is noodzakelijk om de data te hergebruiken”.
Vaak is het heel moeilijk om data geschikt te maken voor meerdere functies bijv.voor omzetten in Narcis en KB etc. Beginnen met Basale ontsluiting en daarna discipline specifieke metadata toevoegen.
20 okt 2011
Het Bureau

Dit najaar ben ik begonnen te lezen in Het Bureau van J.J.Voskuil. Een romancyclus in 7 delen die de dagelijkse gang van zaken verhaalt vanaf de jaren '50 tot '90 op het KNAW-instituut voor Volkskunde (het huidige Meertens-instituut).
Hoofdpersoon is Maarten Koning, die eerst als assistent, later opvolger van A. Beerta afdelingshoofd Volkskunde is.
Sinds 2007 ben ik zelf werkzaam bij KNAW, en ik kan zeggen dat ik het beschreven, de sfeer en de relaties zeer herkenbaar vind.
Het Meertens-instituut zelf ken ik niet zo, maar de omschreven sfeer en het gedachtengoed leeft nog steeds in KNAW-kringen. Prachtig beschreven zijn de soms moeizame contacten met de collega's (sociale omgang was niet Maarten Koning's sterke kant) en zijn overdenkingen, aarzelingen en twijfels.
Het Meertens-instituut heeft wat oude foto's over de tijd waarin Het Bureau speelde op het web gezet en er zijn wat naamsverwijzingen (niet bijgewerkt) gepubliceerd. Interessant is ook het artikel van J. Goossens over het wetenschappelijk bedrijf uit de roman " J. Goossens, ‘Het wetenschappelijk bedrijf in Voskuils roman Het Bureau.’ In: Literatuur 14 (1997), p. 130-137. ".
Fascinerend om te lezen.
Het eerste deel werd gepubliceerd en er was een tijdlang sprake van een literaire hype rondom de cyclus. Nu is er enkel nog een twitter. Maar samen met een collega beleef ik er veel plezier aan.
3 okt 2011
CWTS-cursus meten van wetenschappelijke output 5

Vorige week ben ik 5 dagen lang naar Leiden getogen voor deGraduate Course “Measuring Science and Research Performance” van het CWTS, hetCentre for Science and Technology Studies van de Unviersiteit leiden.
- World of Science, Technology and Innovation
- Research Performance Measurements and Indicators
- Research management perspectives
- Science Mapping
- Science Policy Contexts
- Scientometrics 2.0
Uiteraard is het zorgvuldig interpreteren, verzamelen en schonen van gegevens belangrijk en uiteraard dienen die cijfers in een geheel met andere indicatoren(ook kwalitatieve) gebruikt te worden. Maar soms geven die quick-and-dirty ggevens toch wel een aardig trend aan.
Zelf worstel ik altijd met de onderwerps-indelingen en dat blijkt ook inderdaad een groot probleem te zijn. Om nog maar te zwijgen van de gemankeerde aandachtvoor humaniora in de cijfergegevens. Wellicht dat het met de komst van de BookCitation Index van WoS beter gaat.
Erg interessant vond ik ook de ingangen tot het waarderen van wetenschappelijke onderzoek in termen van economische groei, innovatie en maatschappelijke waardering.



 Als cursusmateriaal kregen we het boek ‘Citation analysis in research evaluation’van Henk Moed, en dat ga ik komende week eens doorlezen, venals ‘The Publish or Perish Book’ van Anne-Will Harzing (hoorde niet tot eesmateriaal).
Als cursusmateriaal kregen we het boek ‘Citation analysis in research evaluation’van Henk Moed, en dat ga ik komende week eens doorlezen, venals ‘The Publish or Perish Book’ van Anne-Will Harzing (hoorde niet tot eesmateriaal).CWTS-cursus meten van wetenschappelijke output 4
Hoe kun je het wetenschappelijk onderzoek meten en de prestaties van universiteiten met elkaar vergelijken?
[In de ranking-systemen worden alleen universiteiten met elkaar vergeleken, omdat er voor onderzoeksinstituten - zoals bijv. het excellent presterende Max Planck Inst. geen vergelijkbare plek is, ook niet voor afzonderlijke onderzoeksinstituten. ook noemt Van Raan het probleem van de academische ziekenhuizen, die vaak verantwoordelijk zijn voor de helft van de output, maar soms moeilijkaan een universiteit te koppelen].
Allen zijn gebaseerd op de 2 commerciële producten (WoS)en (Scopus).
1. TimesHigher Education is ingedeeld in 5 categorien (teaching, research, citations, industry income, international) met een verschillende weging gebaseerd op ‘expert enthusiasm’. 2/3 is gebaseerd op citaties.
2. QS deelt ongeveer in dezelfde categorieen in, maar heeft als extra ‘employer reputation’
3. Shanghai, Academic Ranking of World Universities(ARWU), is heel erg ‘size dependent’. Trotsop oude prijswinnaars, maar zegt niets over potentieel. Bij citaties wordt alleen gekeken naar de highly cited (dus past performance)met nadruk op reputatie.
4. Leidenranking .Het kost veel tijd om websites na te kijken en om netwerk met contactpersonente onderhouden. Ranking op basis van genormaliseerde bibliometrische indicatoren, nu MNCS2 (voorheen CPP/FCSm). Het algemeen plaatje is dat als je als universiteit bij eerste 300 hoort het nog goed zit, daarna gaat de curve scherp naar beneden (hypothese van Raan: er zijn niet meer goede wetenschappers om meer goede universiteiten te bevolken). Voor Frans en Duits zijn aparte lijsten gemaakt.Gemiddelden in studies zijn niet altijd de beste indicator vanwege de ‘skewed distribution’, dan is highly cited beter (A/EPtop10%)
5. U-Multirank, een EU-project.
Naast dit soort ranking kunje ook op andere terreinen aan internationale benchmarking doen. Maar het is lastig om vergelijkbare indicatoren op te stellen.Tijssen geeft een overzicht van de wetenschappelijke indicatoren; technologie-indicatoren (zie ook het University-industry Scoreboard van CWTS); en innovatie indicatoren (bijv. voor het EriC,Evaluation of Research in Context van de KNAW en VSNU is geprobeerd te valoriseren, maar verder dan showcases komt men (nog) niet.
Ook Leru heeft alleen case-beschrijvingen).
Science mapping
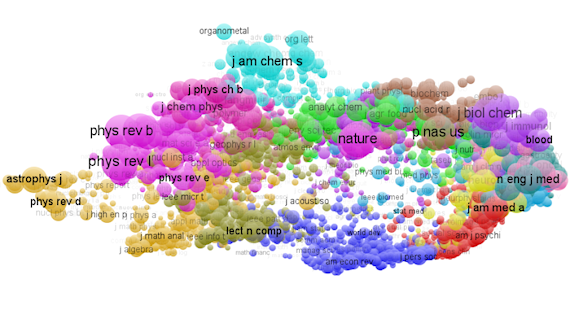
Naast het ranken wordt er m.b.v. allerlei moderne textmining instrumenten geprobeerd de hele wetenschap in kaart te brengen. Kaarten die gebaseerd zijn op de bibliometrische netwerken van publicaties, co-auteurschap, cocitaties e.d.CWTS heeft voor visualisering van die gegevens de zogenoemde VosViewer ontwikkeld. Door de kaarten kun je aldus Noyons en Waltman, dichter bij de data blijven. De kaarten maken clustering mogelijk en kunnen verschillende dimensies weergeven. Van de basis bibliometrische netwerken, maak je afgeleide netwerken die je naar symmetrische matrixen kunt overbrengen en die kun je visualiseren.Zo heeft CWTS bijvoorbeeld alle onderwerpsgebieden uit WoS voor indelen van tijdschriften in kaart gebracht.Dat geeft toch een mooi beeld van de wetenschap en de vertegenwoordiging van artikelen in de WoS-database. [Ik kan me herinneren dat we vroeger zoiets geprobeerd hebben m.b.v. thesauri, maar dat is toen gestrand, ook vw de omvang]. Ook een mooie is de kaart van de tijdschriften zelf:
Cornelis van Bochove neemt een heel andere invalshoek, hij kijkt naar de invloed van Human Resources Management en carrière-politiek op de wetenschappelijke prestaties.Stelling ”Scienceoutput is the sum of competence, aptitude and randomness”. Hij wil onderzoeken of het voor de prestaties wat uitmaakt als je een onderzoeker eerder een vaste aanstelling geeft, dus eerder in zijn carrière uitselecteert. Hij laat met een Pareto-distributie zie hoe dat in de verschillende scenario’s eruit ziet. Als verschillen tussen mensen groter zijn, dan is de invloed van selectie op totale output enorm. Snelle selectie levert dus meer op.Van Bochove kijkt ook naar de economische groei, wat is het aandeel van de wetenschap in de economische groei. Daarbij komt hij tot nogal wat verrassende uitspraken. Fundamenteel onderzoek is nodig om de barriere van de ‘known laws of nature’ te verleggen. Fundamenteel onderzoek vraagt om extra getalenteerde mensen, waarbij de tijdsfactor (=leerfactor) belangrijker is dan geld; meer Einsteins, of rijkere Einsteins hadden niet sneller de relativiteitstheorie kunnen ontdekken. Je krijgt snelle groei als je veel geld stopt in toegepaste R&D op basis van bekende ‘laws of nature’ (zie Azie)Je krijgt stabiele groei op basis van het basic research model afhankelijk van leertijd (zie Japan, vanaf 80 jaren hadden ze niveau van het Westen gehaald en basic research genegeerd toen ging het neerwaarts).De essentie van economische groei zit hem dus, aldus Van Bochove in het Basic Research Model.Die boodschap, om met name te investeren in fundamenteel onderzoek is een interesante gedachte en zal hij uitwerken in een nog te verschijnen artikel.
2 okt 2011
CWTS-cursus meten van wetenschappelijke output 3
Databases en indicatoren.
CWTS zelf maakt gebruikt van de literatuurdatabase van Thomson Reuters (Web of Knowledge) die zij zelf offline ontvangen en bewerken. Uiteraard doen zij ook onderzoek naar de bruikbaarheid van andere databases en in ieder geval is het, aldus van Raan een zegen dat er meer concurrentie (Scopus, Google Scholar) is en dus het monopolie van Web of Science afkalft.
Google Scholar is vrnl. onbruikbaar, omdat er geen gegevens bekend zijn over de dekking daarvan, maar een collega op de ISSI conferentie in Zuid Afrika, zei wel, aldus een van onze docenten, dat hij blij was dat er in ieder geval iets is voor m.n. de humaniora. [Web of Science is erg gefocussed op life sciences en heeft in andere wetenschapsgebieden niet of zeer onvolledige dekking).Scopus wordt steeds beter en steeds completer, hoewel er nog steeds onverklaarbare ‘gaps’ zitten.
impact factor
Uiteraard ken ik de JCR: Journal Citation Report, waarbij Thomson Reuter ieder jaar de impact factoren van de tijdschriften publiceert. Scopus heeft daar een alternatief voor de SNIP. De SNIP index vergelijkt de citaties die een tijdschrift krijgt met de citaties die het (in de referenties bij de artikelen) geeft. En daarmee, aldus van Leeuwen krijg je een normalisatie voor het veld en worden de cijfers beter vergelijkbaar.
CWTS heeft zelf een nog betere indicator ontwikkeld de JFIS (=MNJS), die dus de citaties in een tijdschrift voor het veld normaliseert (afzet tegen het gemiddelde van die onderwerpsgroep) en die bovendien niet alleen naar de citaties uit een bepaald jaar kijkt, maar ook die van voorgaande jaren.Maar omdat ze WoS materiaal gebruiken mag de JFIS niet openbaar.
Dat neemt niet weg dat een gemiddelde zoals de journal impact factor-SNIP-JFIS toch niet zulke goede indicatoren zijn, omdat je bij alle ziet dat de distributie van de citaties ongelijk verdeeld is over de tijdschriftartikelen: een klein deel van de publicaties krijgt het merendeel van de citaties.
Wat indicatoren betreft gebruikt het CWTS het liefst de ‘genormaliseerde’indicatoren, omdat die beter met elkaar vergelijkbaar zijn, omdat omvang en veld waarin gepubliceerd wordt daarmee worden gelijkgeschakeld.
Niet/genormaliseerde indicatoren :
P= number of publications (alleen substantiele bijdrage: article, review, letter)
TCS= total citation score (self citations ignored)
MCS= mean citation score (gemiddelde citatiescore)
Genormaliseerde indicatoren:
MNCS = C/FCS + + de citatiescore gerdeeld door de veldscore = gemiddelde score in een onderwerpsveld
MNJS=JCS/FCS + + en dat kun je ook uitrekenen voor een tijdshcrift alss geheel (JFIS)
Pptop10%= om de zogenoemde ‘outliers’(enkele publicatie die extreem veel geciteerd wordt) er uit te halen en te kijken hoe de prestatie is in het topsegment van het onderzoeksgebied.
Van belang bij het bepalen van een vergelijkbare citatiescore is het citatievenster. Eventueel kun je aan een bepaald documenttype een bepaald gewicht toekennen (bijv een ‘letter’ telt dan minder zwaar als een volledig artikel).
Ludo Waltman, die de indicatoren presenteert gaat ook nog in op de h-index met de woorden ‘gebruik nooit de h-index’, iets waarover hij ook zal publiceren in JASIST.
Wat is er mis met de h-index?
De h-index geeft het kruispunt aan van aantal publicaties en aantal citaties per publicatie van een onderzoeker. Volgens CWTS-berekeningen is dat een inconsistente indicator, hij toont nl bij gelijkblijvend gedrag niet een gelijkmatige verhoging van de index. De h-index kan nooit omlaag gaan en ook nooit hoger worden dan aantal publicaties. Ook normaliseert hij niet naar verschillen in het veld, naar leeftijd en lengte van de wetenschappelijke carriere van de onderzoeker, en naar zijn gekozen publicatiestrategie.
Kortom het deugt niet.
[ Jammer genoeg is het wel een erg handig getal, wat tamelijk makkelijk zelf te produceren is zonder ingewikkelde berekeningen en toegang tot moeizaam verkregen gegevens. En zolang daarvoor i de plaats geen net zo handig hanteerbaar instrument voorhanden is zal dat ook wel gebruikt blijven, denk ik.]
Het alternatief wordt tijdens de cursus ook aangereikt: dat is wat de CWTS al doet door in samenwerking met onderzoekers en tegen de achtergrond van het onderwerpsgebied, genormaliseerde gschoonde citatiegegevens te gebruiken samen met kwalitatieve peer evaluatie.Grootse problemen bij alle indicatoren zijn er doordat onderwerpsclassificeringen niet helder zijn en er een betere methode zou moeten worden gevonden voor het contextualiseren van het onderwerpsgebied waarin onderzoeker/onderzoeksgroep werkzaam is.
Robert Tijssen gaat nog in op het begrip 'excellence'.In de huidige praktijk worden universiteiten, onderzoeksgroepen en -instituten iedere zes jaar ge-evalueerd volgens het SEP (Standaard Evaluatie Protocol). Het SEP geeft ook de definities voor de classificaties "excellent", "very good", "good" etc. Hoewel collega van Leeuwen eerder zei "er is geen directe link tussen citaties en kwaliteit, het moet altijd via 'impact'lopen " loopt het meten van kwaliteit toch vaak over het meten van impact. CWTS beveelt wel aan de gehele portfolio van kwalitatieve peer review en kwantitatieve scientormetrische gegevens te hanteren. Toch geeft een 'highly citated' analyse wel een indicatie van goede kwaliteit.Aardig is het onderzoek naar bibliometrische gegevens van Spinozaprijswinnaars. "De NWO-Spinozapremie is de hoogste Nederlandse onderscheiding in de wetenschap". Als je de resultaten van de Spinozaprijswinnaaars-kandidaten met de indicator MNSC kalibreert kom je gemiddeld op 2.1 (2x het wereldgemiddelde), kijk je alleen naar de winnaars dan kom je uit op 3 (met een standaard deviatie van 1.7 - meestal humanoria). Dat geeft toch aan dat je met die indicator, mits gekalibreert naar veld wel iets kunt zeggen.Ook blijkt dat Thomson Reuters er in zijn voorspellingen naar de Nobelprijswinnaars redelijk vaak raak schiet.Voor profilering van een onderzoeksgroep is het wel noodzaak de uitschieters eruit te halen, dat is geen voorbeeld van excellence. Dat kun je doen met de A/EPtop10% of zelfs A/EPtop1% scores.
1 okt 2011
CWTS-cursus meten van wetenschappelijke output 2
Maatschappelijke relevantie en de waarde van de wetenschap voor innovatie.
Prof Robert Tijssen gaat in op kenmerken van wetenschap en innovatie, hoe kun je wetenschap, de bijdrage van de wetenschap aan innovatie i.c. innovatieve producten herkennen?
De outputs zijn niet alleen publicaties, maar ook standaarden, training van Phd’s, patenten e.d., die hebben impact op de media en overhead en dat leidt tot beleid en economische inpassing in nieuwe processen en producten. Daaruit vloeien dan weer de ‘outcomes’ voort, de maatschappelijke en commerciële opbrengsten.
Om die opbrengsten en invloeden te meten kun je verschillende toolboxen gebruiken waaronder bibliometrische studies )maar ook econometrische en management studies en surveys.
Het is nog niet zo eenvoudig om de invloed van wetenschappelijk werk te meten, omdat je eerst moet weten wie de gebruikers zijn en wie er van profiteren, omdat er vaak sprake is van meervoudige invloeden. Ook kan er soms een behoorlijke tijdspanne zitten tussen onderzoek en een meetbaar resultaat. Causaliteit blijft moeilijk aantoonbaar.
Anders dan bijv. bibliometrische citatiepatronen laten ook surveys een overzicht zien van de waarde van de wetenschap. Bijvoorbeeld in een survey heeft de EU laten onderzoeken wat de houding van Europeanen is t.a.v. de wetenschap (Eurobarometer 340). Daaruit blijkt dat toch meer dan de helft van de bevolking positief staat t.o.v.de wetenschap en de maatschappelijke bijdrage van de wetenschap. Later in de week laat Ingeborg Meijer ons zien dat er naast bibliometrische methoden en survey’s nog andere methoden zijn om het maatschappelijk belang van onderzoek te meten. Zij hebben dat gedaan bij LUMC. Dat is wel een aardige aanvulling i.v.m. toenemend belang van ‘valorisatie’ (maatschappelijke waarde, ook ondernemerschap of publiek-private samenwerking).
Wel kom je, aldus Meijer snel in discussie terecht over meten van wetenschappelijke resultaten: kwantitatief vs kwalitatief, strikt wetenschappelijk en/of valorisatie, welke indicatoren je gebruikt en hoe die ingezet (c.q. gemanipuleerd )kunnen worden.
De methodologische vragen naar de robuustheid van de systematiek en de waarde ervan, m.n. vanwege het ontbreken van de relatie tot de wetenschappelijke kwaliteit.
Toevalligerwijs is er net die dag een onderzoek gepubliceerd van een consultancy bureau dat de economische verdiencapaciteit van de universiteit Leiden heeft gemeten en tot de conclusie komt dat leiden 4x zoveel opbrengt als het kost.
Tijssen laat in een aardige grafiek uit Google labs zien dat je bijvoorbeeld met Google books een aantal onderwerpen kunt vergelijken door in de full text van boeken te zoeken en te kijken naar het voorkomen van het gebruik van die termen (termen als innovatie, bibliometrics).
29 sep 2011
CWTS-cursus meten van wetenschappelijke output 1
Op maandag 26 september 2011 komen in een veel te klein zaaltje in het Willem Einthoven-gebouw van de Universiteit Leiden, 20 studenten samen voor de cursus “Measuring Science and Research Performance” van het CWTS. Het CWTS is de afdeling van de Universiteit Leiden die door bibliometrisch onderzoek wetenschaps- en technologie indicatoren berekent en de onderzoeksresultaten van een universiteit of afdeling bibliometrisch onderzoekt. CWTS heeft daarin wereldwijd een grote naam opgebouwd. De studenten komen dan ook uit 9 verschillende landen
De eerste dag heeft een inleidend thema:’de wereld van de wetenschap, technologie en innovatie’.
Paul Wouters, directeur van het CWTS, opent met een eerste inleiding over het vakgebied van de ‘scientometrics’.
Beginnend met het filmpje “Science is real”. Dat aangeeft waar het bij wetenschap om gaat, om de content. Voor scientometrische beschouwingen worden citaties uit die werkelijkheid van de content gehaald en als zelfstandige entiteiten behandeld (verzameld en geteld).
Terwijl in de cirkel van onderzoek het debat, de peerreview, de interactie met collega’s centraal staat, heeft de cirkel van de citaties een eigen focus van aantallen. Paul schildert de opkomst van citatietellingen, vanaf 1873.
Paul Wouters, zelf gepromoveerd op “The Citation Culture”wat de geschiendenis van de Science Citation Index beschrijft, schildert de opkomst van citatietellingen, vanaf 1873.
Hij concludeert bij de opmerking dat Garfield al in 1955 bij zijn eerste idee van een citatie index, veel afwijzende reacties kreeg, dat in wezen de kritiek nog steeds dezelfde is “een citatie zegt niets over de publicatie zelf’.
Zie ook de beschrijving van de citation index in WikipediaR!=C reference is the inverse of the citation
Een citatie gebruiken als indicator voor een publicatie is geen natuurlijk proces, het komt niet voort uit de wetenchapo zelf. Een citatie is veel meer een teken van erkenning in de reputatie-competitie.
Een basisvraag blijft dan ook ‘waarom wordt een werk geciteerd’? Dat citatie-gedrag is tamelijk lastig omdat het geen wetmatigheid betreft maar een psychologisch, sociologisch en cultureel bepaald proces is. De huidige dominante theorie is de normatieve theorie, gebaseerd op de ideeen van Kaplan, N. The norms of citation behavior: Prolegomena to the footnote. American Documentation 16, 179-184, doi:10.1002/asi.5090160305 (1965).
Ton van Raan vervolgt, als nestor van de club, met een uiteenzetting over de ‘basics’van de bibliometrie:
1. Netwerken: primair citatie netwerk, co-citatie netwerk, bibographic coupling
2. Kennisvelden, breng de wereld in kaart m.b.v. door citaties gerelateerde word countings n een driehoek
3. Genormaliseerden onderwerpsvelden , en naar tijd genormaliseerde citatievensters
Bibliometrisch onderzoek kun je top down benaderen, gebaseerd op veld structuren, of bottom up, waarbij de auteur de gegevens kan inbrengen.
Belangrijkste indicatoren zijn: P (publicaties), C+sc (citaties), CPP (citaties per publicatie), Pnc (publication not cited = time depended)en top 10%.
De zogenoemde ‘crown indicator’is de CPP/FCSm (dus de citaties per publicatie gedeeld door gemiddeld aantal citaties per veld) Dat boven 1 moet zijn.
[Tegenwoordig hanteren ze de MNCS mean normalized citation score, waarbij ook het gemiddelde van het tijdschrift wordt meegeteld].
Wat kun je met bibliometrics?
* Invloeden meten van wetenschappelijk werk
* Patronen ontdekken in de structuur van de wetenschap.
Tegenwoordig wordt meestal de term 'scientometrics' gebruikt, om aan te geven dat er bij evaluaties naar meer wordt gekeken dan alleen naar citaties van publicaties.
Scientometrics is ook de term voor organisaties rondom dit thema.
Zo is er een European Summer School of Scientometrics, die van 11-16 september gehouden werd, en die vlgs een Zweedse mede-cursisten al helemaal was volgeboekt. De presentaties zijn op de website gepubliceerd en omvatten dezelfde thema's als in de CWTS-cursus: citaties, indicatoren, science mapping.
Ook is er een International Society for Scientometrics and Informatics, die in juli 2011 heeft gecongresseerd in Durban, Zuidafrika. ieder 2 jaar wordt door ISSI een congres georganiseerd, en meestal in het tussenliggende jaar organiseert CWTS een 'Conference on Science and Technology indicators'.
Er bestaat een tijdschrift gewijd aan de onderwerpen die in dit vakgebied een rol spelen getiteld Scientometrics, en een ander belangrijk tijdschrift is JASIST, Journal of the American Society for Information Science and Technology.
18 aug 2011
Trends Academische Bibliotheken
ls aanvulling op mijn eerder berichtje over de toekomst van de academische bibliotheek hier een kort overzicht van een nieuwsbericht uit College & research Libraties news.
"2010 top ten trends in academic libraries: A review of the current literature" by ACRL Research Planning and Review Committee
1) Academic library collection growth is driven by patron demand and will include new resource types.
Collectievorming gaat van 'justincase'naar 'justintime'. gebruik maken van patron-driven acquisition formaten. Locaal materiaal wordt gedigitaliseerd en toegang tot ful text en tot datasets wordt gemeengoed.
2) Budget challenges will continue and libraries will evolve as a result
Door budget reducties wordt het moeilijker adequaat personeel aan te trekken,toegang tot bronnen te verwerken en innovaties door te voeren.
3) Changes in higher education will require that librarians possess diverse skill sets
Bibliotheekpersoneel moet voortdurend bijgeschoold worden. ook zullen meer niet-bibliotheekgeschoolde medewerkers in het vak intreden
4) Demands for accountability and assessment will increase.
Aan bibliotheken wordt gevraagd de toegevoegde waarde van hun diensten aan te tonen.
5) Digitization of unique library collections will increase and require a larger share of resources
6) Explosive growth of mobile devices and applications will drive new services.
7) Increased collaboration will expand the role of the library within the institution and beyond.
8) Libraries will continue to lead efforts to develop scholarly communication and intellectual property services.
9) Technology will continue to change services and required skills
10) The definition of the library will change as physical space is repurposed and virtual space expands.
21 jun 2011
Store-Share-and-Cite
Donderdag 9 juni werd in de Oranje-zaal in de bibliotheek van de TU Delft een minisymposium gehouden onder de titel ‘Store-Share-and-Cite: Increase your citations by (re)use of research data’.
Het blijkt al de derde bijeenkomst te zijn van 3 TU over Research Data Management. Het verslag van een eerdere bijeenkomst heb ik teruggevonden (22 april 2010 ‘Exciting Research Data’).
Als symbolisch deelnamekado krijgen we een velletje met bloemenzaadjes: dat zowel 3TU Datacentrum als de zaadjes mogen bloeien! Er is helaas geen open wifi, er is wel een hashtag #3tudatacitation maar die is te lang dus ik gebruik #3tudcit. In de pauze wel een stopcontact gevonden, maar de laptop werd helaas niet geladen.
Maria Heine, directeur bibliotheek TU Delft, opent met welkomswoord en middagvoorzitter Erik Soonieus, TUD alumnus introduceert de sprekers.
De eerste spreker is Michael Diepenbroek , hij vertelt over ICSU World Data System, dat gestart is in 1957 t.g.v. het Geophysical Year. De ICSU (International Council for Science) een samenwerkingsverband van Wetenschapsacademies is oprichter van het World Data Center System “The World Data Center system works to guarantee access to solar, geophysical and related environmental data”.
- NB het ICSU Word Data System confereert in september a.s. in Japan.
Diepenbroek, is verantwoordelijk voor Pangea. Pangea volgt de principes en richtlijnen van het World Data Center System.
"The information system PANGAEA is operated as an Open Access library aimed at archiving, publishing and distributing georeferenced data from earth system research. The system guarantees long-term availability of its content through a commitment of the operating institutions".
Voor Pangea heeft hij een model data management opgesteld n.a.v. IODP (Integrated Ocean Drilling Program).
Diepenbroek: “Het grootste probleem is niet technisch van aard, maar semantisch” Bij Pangea werken ze met meerdere projecten, die hebben een eigen portal en geven ook input voor bijv. GBIF en OBIS en ze werken als data warehouse, met diverse standaards voor content en interfaces. Zelfs binnen één community meerdere standaards. Ze doen al 15 jaar aan datapublicatie en hij gaat zelfs zover dat hij zegt dat de enige data die het waard is bewaard te blijven gepubliceerde (= gepeerreviewde) data is.
De 2e spreker Patrick Vandewalle (heeft blog pixeltje.be) is een oud-TUDelft student. Hij spreekt vanuit zijn ervaring bij het schrijven van zijn PhD in Lausanne, het gebruikersperspectief over ‘signal processing’. Hij kreeg vaak de vraag of men zijn test kon herhalen en daarom besloot hij alle gegevens van die tests vrij te geven.
Hij heeft daar zelfs ook een artikel over geschreven ‘Reproducible research in signal processing’ IEEE Signal Processing Magazine 2009 pp 37-47. Hij geeft hoog op van de voordelen voor hemzelf en voor de wetenschap en heeft daar zelfs een website aan gewijd
Het basisprincipe van wetenschap is herhaalbaarheid van de experimenten. Daarop is alles gebaseerd en dat maakt het meer efficient en robust. Geeft je de gelegenheid om zelf verder te werken,zodat anderen jouw werk als uitgangpsunt kunnen nemen en anderen om jouw werk als bouwsteen te nemen en het verhoogt de impact. Zijn werk bestaat uit theorie, rekenwerk en experimenten. Daarvoor zijn verschillende gegevens nodig om dit herhaalbaar te maken. Hij heeft zijn eerste artikel reproducible gemaakt door het inclusief de matlab code online te zetten.
Maar het is nog veel efficienter als je van te voren al weet dat je iets reproducible wilt zetten.
Hergebruik voor hemzelf was efficient, mooi demo materiaal, heel veel downloads, mooie reacties en samenwerking (beter om op je schouders te staan dan op je tenen)
Hoe maak je het reproducible:
- Als supplementary material bij publicatie
- Apart in een repository in Eprints
Papers available online are cited 3x more often [Lawrence Nature 2001 `Free online availability substantially increases a paper’s impact´ Piwowar in PlosOne 2007 ‘Sharing Detailed Research Data Is Associated with Increased Citation Rate’
Philippe Terheggen van Elsevier belicht ten slotte de rol van de uitgever. De komende 50 jaar, Aldus Terheggen gaan over datamining (4th paradigm zie Harvard business review 2010 )
“Access vs importance : datasets are seen as important but accessible is usually low”
Er zijn 4 soorten verrijkte publicaties:
1) supplementary data, (maar er zijn geen middelen om supplements 200 jaar te onderhouden)
2) article linking, (link van een database naar het artikel. De auteur post de link automatische connectie met Elsevier (Nextbio)
3) entity linking,(v an een ander niveau is als je een link hebt in het artikel naar een code met een link naar de data. De auteur heeft die link getagged)
4) embedded apps(PDB Proteine database geeft visualisatie in het artikel en bijv ook Pangea)
Altijd op een non-inclusive basis, de bedoeling is dat het denktijd vermindert die nodig is om naar informatie te komen. “General vision to increase discoverability of science by universal access and integration to data and tools”
Vraag: hoe kun je een artikel meer interactief maken ? bijv. redactioneel comentaar per artikel, misschien ook een discussiepagina, maar hoe kun je dat onderhouden voor al onze tijdschriften?
Copyright is een grijs gebied, er rust geen copyright op supplemnetary data. Copyright gaat vrnl over het format van het artikel.
Jeroen Rombouts 3TuDatacentrum 'Science data services Nl' schets de ‘ANDS Data Sharing Verbs’ Approach , een sort data lifecycle van de Austtralian national data services
Create, Describe & Store, Identify & Rgister, Discover & Access, Exploit
3tuDatacentrum levert 3 diensten:
1) archives (datacite.org = persistent identifier) selection, types;
2) data-labs for working version;
3)data-services like advice, training
Na deze inleidingen wordt er een panel samengesteld uit de sprekers en wij allen in de zaal mogen met stemkastjes (turningpoint click device) op een stelling stemmen.
Stellingen:
1) Every dataset has to be accompanied by publications Y=59% N= 41
JR zou niet verplicht moeten zijn anders word took nutteloze data opgeslagen
Andersom juist wel
Data met metadata kan veel belangrijker zijn dan zonder data
2) Citation to artical with data shoud account for ..% without wegingsfactor (onduidelijk)
3) Citations should contribute to IF of journal (
Zolang je geen credits krijgt voor datasets
4) Change IF to include datasets
5) PhD moet 1 dataset produceren
De stellingen waren niet allemaal even duidelijk, en over de meeste waren we het wel eens: geen dwang, wel faciliteren en financieren.
31 mei 2011
Toekomst academische bibliotheek
Waar zijn we over 5 jaar?
Al sinds het begin van de automatisering – digitalisering van de informatie in het algemeen wordt er gesproken over het voortbestaan van de bibliotheek en de bibliothecaris. Van de opleidingen mocht het beroep niet meer met ‘bibliotheek’worden aangeduid en er volgde allerlei varianten met het woord ‘informatie’ in de titel. Een beetje lastig is dat wel, want je kunt niet meer makkelijk zien in welke categorie iets of iemand valt. Het woord ‘informatie’wordt ook breeduit gebruikt in de automatisering en in bedrijfskundige administratie.
Enfin zelf heb ik ook wel eens een scriptie(tje) geschreven over “de veranderende rol van de bibliothecaris”. Is nog steeds online te vinden en ik sta er ook nog wel achter.
Het basisidee is dat de kern van de bibliotheek en zijn functionaris, niet is dat het een ‘bewaarplaats van boeken is, maar een toegangspoort tot allerlei vormen van gedigitaliseerde informatie. Zoals in een artikel in Chronicle : “Libraries never were warehouses of books. While continuing to provide books in the future, they will function as nerve centers for communicating digitized information at the neighborhood level as well as on college campuses.”
Waar de een, zoals Mackenzie Owen in IP het verwoordt, de overbodigheid van de bibliotheek ziet, ziet de ander de bibliotheek juist groeien. Niet alleen in het fungeren als ‘learning space’(zie ‘de UB als learning space”van G.Lutgens en G.Goris etc) maar ook met de nadruk op speciale informatiediensten. Te denken valt dan aan training in informatievaardigheden en eigenlijk een geheel scale aan ondersteuning in academische vaardigheden. Ook bijv. de support bij het managen van research data hoort daarbij, alsmede het verhogen van het bewustzijn van het belang van informatie en data bij de onderzoekers.
Waar soms ICT-afdelingen en bibliotheken fuseren danwel samenwerken op basis van hun samenkomst op het gebied van software/automatisering, daar spreekt Sue McKnight “Adding value to larning and teaching’ liever over het vormen van organisatorische ‘academic services hub’ een club mensen die de leerervaringen van studenten kunnen transformeren. Ze heeft het dan over testomgevingen in VLE (Virtual learning environments, het toevoegen van content aan nieuwe technologieen.
Het toevoegen van 2.0 diensten behoort ook tot de bibliotheekontwikkeling, speciaal gericht op de digitale, mobiele gebruiker en het vinden van nieuwe wegen om die gebruiker te bereiken
J. Neal en D.Jaggars schrijven het als volgt: “If academic libraries hope to support current and evolving informatonseeking behaviours, they must íntegrate in their users’ network-based workflows by exposing as much content as possible to search engines, making it discoverable where users are most likely to be working.”(Web 2.0).
De rol van de bibliotheek bij het wetenschappelijk publicatieproces wordt groter met de grotere nadruk op open access en grotere toegankelijkheid van informative. Zeker indien het verbonden is met abonnementsprijzen en kosten. Nu al is het gebruikelijk dat de bibliotheek informatie geeft over Open Access publiceren, en het beheer van repositories met daarin het depot van de eigen publicaties. Langzamerhand wordt dit uitgebreid met het depot van data en het managen van research data. Martin Lewis omschrijft in :” The Management of research data” een aantal eisen / activiteiten , zoals adviseren en trainen van onderzoekers op gebied van omgaan met data.
Al deze aangehaalde auteurs hebben een hoofdstuk geschreven in het document ‘ Envisioning future academic library services’ ed by S.McKnight Facetpublishing, 2010
Ook de ARL (Aacademic Research Libraries( en de ALA (American Library Association) hebben documenten gepubliceerd met toekomstvisies, soms zelfs hele scenario’s. De meeste komen min of meer op hetzelfde neer.
De taken en behoeften blijven wel bestaan, meer dan ooit is toegankelijk maken van informatie gevraagd, moeten informatievaardigheden ontwikkeld worden en onderzoekers begeleid en ondersteund. Maar zoals Mckenzie Owen opmerkt, of dat nu in een bibliotheek moet? Ja dat is de vraag, enerzijds wat is er specifiek bibliotheeks aan een high tech project- en samenwerkingsruimte?
Bij veel bibliotheken zie je ook een zijtak als het ondersteunen van het onderzoeksregistratiesysteem (METIS) en bibliometrische diensten. Het is logisch dat zich dat in de afdeling bibliotheek ontwikkelt omdat de bibliotheek al in ondersteuning doet, hetom informatie gaat en raakvlakken heeft met ICT. Maar het hoeft niet en niet voor iedereen is die link meteen gelegd.
In de praktijk is het grote voordeel om als onderzoeksondersteuner in de bibliotheek te werken dat er een ‘ neutrale’ ruimte is. Dat maakt het makkelijker, laagdrempeliger voor de ondersteuning. Maar die fysieke ruimte, met name het boeken-bewaarplaats gedeelte boet wel in aan belang, wat dan nog blijft is een soort van high tech lab, waar je gadgets en tools kunt testen. Ook leuk, interessant en nuttig, maar de raakvlakken met een bibliotheek zijn dan wel erg theoretisch geworden.
De grote universiteitsbibliotheken zullen hun collecties gaan samenvoegen en – zoals ook alle andere informatie op internet als gezamenlijk bezit presenteren. Zoals Lukas Koster en Rosemie Callewaert schrijven “To summarise: the new digital and networked nature of collections of information leads to a focus on new information services, supported by library staff with information and technology skills, in new organisational structures and in cooperation with other organisations.”
Collecties zijn voor kleine academische bibliotheken, zoals de NIOO bibliotheek dan overbodig, zeker als alle wetenschappelijke literatuur open access digitaal toegankelijk is.
Jammer vind ik het wel, maar ik denk toch dat langzamerhand de bibliotheek verdwijnt en daarvoor in de plaats een afdeling Research Information Support komt, hopenlijk met inderdaad een soort ‘ knowledge experience’ center om gagdets, games en tools te testen en te introduceren. Zeker ook met taken op het gebied van de informatie- en academische vaardighedentraining, publicatiebeleid en open access, onderzoeksregistratie en data-archivering. Ook het bijhouden vna portals en ingangen is een mooie taak om toegang voor de eigen groep te stroomlijnen. Onderwerpen genoeg en die blijven heus wel.
Referenties:
McKnight, Sue ( editor) Envisioning Future Academic Library Services: Initiatives, ideas and challenges . Facetpublishing., 2010. ISBN: 978-1-85604-691-6
Staley, David J. and Malenfant, Kara L. (eds.) Futures Thinking for Academic Librarians : Higher Education in 2025. ACLR (Association of College & Research Libraries), 2010.
Mackenzie Owen, John. De Nederlandse Bibliotheek voor het onderwijs: toekomst Hogeschool- en Universiteitsbibliotheek. in: Informatieprofessional (2011) nr 4 p. 18-21.
Lutgens, G. en G. Goris. De UB als Learning Space. In: Informatieprofessional (2010) nr. 11/12.
Koster,Lukas en Rosemie Callewaert. Dicovering The Library Collections: library traditions in the light of the web and its users.
Toegevoegd 7-6-2011:
Verslag van het symposium "Future of Academic Library May 16.17 2011" in Library Journal
20 mei 2011
Open Onderzoeksdatadag
Open Onderzoeksdata dag van Surf georganiseerd in het Trippenhuis van de KNAW, maar georganiseerd door Surffoundation om te laten zien wat de diverse deelnemers als voor activiteiten ontwikkelen op het gebied van onderzoeksdata.
Directeur Surf opent Open Onderzoeksdatadag met beschrijving van populaire, maar al oude thema's: "cloud" en "open". De begrippen zijn niet nieuw en al tientallen (cloud/web) zo niet eeuwen (open) oud, maar de ontwikkelingen gaan traag, kijk bijv. naar de Berlin Declaration die toch al in 2003 door bijna alle partijen getekend is. Maar Open Access is nog niet echt doorgebroken. Wel veelbeleovend is het feit dat gisteren minister Verhagen van bij de opening vna de digitale agenda sprak over het inrichten van een Open Dataportaal voor overheidsinformatie. (zie info van ministerie, ook Neelie Kroes heeft over Europese open data geblogd)
De Keynote wordt uitgesproken door Jan Luiten van Zanden: “2+1 argumenten voor data-delen” over global economic history ofwel hoe overtuig je collega's van het belang van open opslag
Ook van Zanden is geennieuweling op dit terrein, zo heeft hij al in 2006 een basisartikel geschrven over samenwerking onder de titel ‘Do ut des. Collaboratories as a "new" method for scholarly communication and cooperation for global and world history” [Do ut des = Geef opdat gegeven zal worden] Hij leidt nu een groot project CLIO-INFRA, dat bestaat uit hubs, die samenwerken in collaboratoriess.
Wat zijn nu zijn argumenten voor open data:
- morele argumenten: voortgang van de wetenschap en maatschappelijke investeringen
- nieuwe publikaties mogleijk door samenwerking en vergelijkingen
- workshops voor uitdragen van kennis
- geld, aantrekken van nieuwe geldbronnen
- gezag en het verkrijgen van autoriteit
Hij komt met een mooi historisch voorbeeld over het onbedoeld gebruik van het VOC-archief, doordat bleek dat daat gegevens inzitten over bevolkinssamenstelling van Sri Lanka in die tijd.
De argumenten voor het delen van data zijn: efficiency, sommig onderzoek alleen mogelijk door vergelijking, disciplinerende werking Data Availability Policy [= eis van tijdschriften dat data gedeponeerd wordt).
Voorts komt Wilma Mossink van Surf. Zij bespreekt de rapporten van werkgroep Toegang tot Onderzoeksdata en geeft de handige verkote URL: http://www.surffoundation.nl/ToegangtotOnderzoeksdata . Dat is een iets andere link dan die naar de site van Open Onderzoek, die we (ik) eerder gebruikte.
Over de meeste heb ik geblogd in het kader van een bijeenkomst van het Onderzoeksdataforum.
Ze bespreekt ook al enkele rapporten, dioe nog niet gepubliceerd zijn, zoals het witboek dataprofessionals (werk ik zelf aan mee), DIPP over publiek private samenwerking en CARDS over veilig opslaan en gecontroleerd delen van data.
Ook stipt Wilma Mossink het project PersiD aan over persistente identifiers.
En de algemene aanbevelingen daaruit, voor NWO-KNAW, voor VSNU, voor de uitgevers en voor de instellingen. De deelnemers hebben dit allemaal op een A4-tje meegekregen, ik heb het in dropbox gekopieerd.
Theo Mulder, directeur onderzoek KNAW (en dus ‘onze’ hoofd-directeur) schets het KNAW-perspectief . Hij opent wel heel illustratief door Nederland te schetsen door de ogen van een Amerikaan als ‘shoppingarea’. Wat zijn de argumenten voor open onderzoeksdata? Mulder noemt drie argumenten:
- belastingbetalerargument,
- versnelling van wetenschap en
- kenniscrisis = aantasting legitimiteit van de wetenschap
Extra aandachtspuntje: bij de data zou ook de software open (open source) moeten zijn.
De rol KNAW is daarbij beprkt tot wat zij zelf voor de instituten voorschriven. Onlangs is er een beleidsnotitie ‘Open Access en Digitale Duurzaamheid’ uitgegaan ; er is geld gereserveerd voor Open Access, ieder instituut moet een datanotitie schrijven en iedere onderzoeksplan moet een dataparagraaf bevatten. Er is een ondermeer een flyer gemaakt met meer informatie. Mulder pleit ook voor schaalvergroting (internationalisering): een mogelijkheid om aan het ‘shoppingarea’effect te ontkomen.
Ron Deker van NWO belicht vervolgens het standpunt van de NWO. Ook zij zijn voor open data en ook hij stipt DANS aan het gezamenlijk instituut van KNAW en NWO, dat een voorziening biedt voor het opslaan van data. Hij haalt ook Minister Verhagen aan die die expliciet heeft gezegd "publieke data = open data = gratis data". NWO hanteert een duidelijk onderscheidt tussen publicaties en data. Bij data blijft NWO mede-eigenaar, data moet daartoe goed gedocumenteerd opslaan
NWO wil de bewustwording stimuleren.
Open data is het kunnen verschaffen van toegang (techniek) en het toegankelijk maken (juridisch-inhoudelijk). De beweegredenen van het delen van data zijn: kennisdelen en efficiency (hergebruik).
Als geldschieter kijkt NWO graag naar de efficiency van de subsidie :zij financieren liever één topfaciliteit dan 2 of 3 middelmatige. Zij zijn voorstander van goede citatie (kan door persistent identifier), en ziet problemen bij attributie (erkenning). Uit het publiek vertelt een deelnemer over het gebruik van ISBN aan datasets (bij taalkunde).
Peter Doorn van DANS spreekt als laatste over Dans en over “ Duurzame toegang tot onderzoeksdata”. Hij noemt Easy.dans.nl een soort Youtube voor onderzoeksdata. Hij verhaalt over de historie van Dans: uit 2005 en voorganger Steinmetz archief: over de functies als archief, advies- instelling , keurmerk. Dans heeft proef gedaan met data reviews (online) met een positief resultaat. Er is een rapport van op te halen op de op danssite.
Doorn geeft als aanbeveling mee, om onderzoeksdata te registreren in Research Information Systeem, actueel in Nederland is dat het Metis-systeem.
Ter afsluiting een paneldiscussie: Olv Leo Verdonschot
In 2 minuten mogen de panelleden een stelling verkondigen waarna een discussie volgt.
* Barend vd Meulen van Rathenau: Onderzoeksresultaten zijn niet uitsluitend afhankelijk van de meetbare prestaties. Ligt bij onderzoekers zelf, die kunnen niet meetbare resultaten, zoals datasets opnemen in zelfevaluatie.
* Karel Moons UMCU: Geneeskundig onderzoekers zijn huiverig om kennsi te delen. Ze zien op tegen het veel werk om gbegevens te anonimiseren. Maar ze zijn vooral bang dat ‘anderen’ meeliften met het vele werk dat zij gedaan hebben, zij zijn bang voor onkundig gebruik, onderuithalen van publicaties, who guards the guardians. Er zijn tijdsbeperkingen nodig( bijv. de tijd, die nodig is voor de originele onderzoeker om te promoveren) en publiceren Good Scientific Practice Guidelines
* IJsbrand Aalbersberg van Elsevier houdt zich bezig met het linken van publicaties met data. Elsevier is geen voorstander van copyright op datasets. Ze willen het liefst data in disciplinegeridchte repository met een aggregator als datacite. De data zo goed en rijk mogelijk linken op meerdere niveaus en binnen artikelkan dan een windowgeopend worden voor datarepository.
* Maria Heine, UKB en TUDelft van push naar pull: de 3TTU Datacentrum gaat samenwerken met Dans als centraal expertisecentrum (ev in overleg met e-sciencecentrum) en decentraal opgezet netwerk van locale frontoffice
Laatste vraag “waarom houden de instituten tegen webtrends in de informatie die zij met belastinggeld vergaard hebben voor zichzelf" Ze zien de directe winst niet en ‘voor de een een vak, voor de andere een hobby’
Interessante dag (presentaties en video staan online) , met name doordat het een soort state-of-the-art vertegenwoordigde van de grote financierende instellingen als NWO en KNAW. Waar staan we nu? Het antwoord is: “open als het kan beschermd als het moet”.
Ondanks het hoog mannen-in-pak-gehalte toch een gedenkwaardige middag, wat in ieder geval nog wel gevolg kan hebben voor de positie van de onderzoeksdata in Nederland met wat mij betreft als kernwoorden:
- Meer aandacht - bewustwording
- Zoveel mogelijk open
- Schaalvergroting
- Disciplinegericht