Overzicht van mijn 'gelezen' lijst voor 2009 en 2010: (voor 2008 zie voorgaand verslag)
**
Lanting, Menno. Connect!: de impact van sociale netwerken op organisaties en leiderschap. Amsterdam [etc.]: Business Contact, 2010.
**
*Chris Anderson .Free: The long tail: Hoe het nieuwe Gratis de markt radicaal verandert . Nieuw Amsterdam, 2009. http://lifehacking.nl/algemeen/free-artikel/ (Gratis e-book)
**
*Darwin, Charles, and Fieke Lakmaker. De autobiografie van Charles Darwin, 1809-1882: de oorspronkelijke versie. Amsterdam: Nieuwezijds, 2008.
Nuchter en helder geschreven overzicht van zijn leven en werk. Zie mijn logje met opmerkelijke uitspraken.
**
* Volledig communicatiegeorienteerde informatiemodellering FCO-IM, met bijbehorende case-tool. / door Guido Bakema, Jan Pieter Zwart en Harm van der Lek. Academic Service, 2005. ISBN 9039524181
FCO-IM is de facto standaard voor databaseontwerp.FCO-IM staat voor Fully Communication Oriented Information Modelling. Dit is een leerboek met opdrachten, voorbeelden en tips. FCO-IM is opvolger van NIAM (Natuurlijke taal Informatie Analyse Methode). Ook de FCO-Im -informatiegrammatica maakt gebruik van natuurlijke taal zinnen. Het classificeren (indelen in groepen) en kwalificeren (betekenisvolle naamgeving) moet identificeerbare en redundantievrije objectbeschrijvingen opleveren. In het Informatiegrammaticadiagram worden de verschillende tyoen in hun onderlinge samenhang getoond. Het gaat om feittypen, labeltypen, objecttypen, feittypeexpressies en objecttype-expressies. Hoewel op het eerste gezicht sommige begrippen wat moeilijk overkomen is het geheel helder uiteengezet.
**
* Budd, J. (2008). Self-examination: The present and future of librarianship. Westport, Conn: Libraries Unlimited.
John Budd schrijft in een lange monoloog zijn visie op de wereld, waarbij ook bibliotheken aan bod komen. Op de achterflap staat : "Through intellectually rich and engaging entrees into ethics, democracy, social responsability, governance and globalization ..."e ja, die onderwerpen zijn allemaal voorbijgekomen in dit 281 pagina's tellende boekwerk. Als hij de 7 hoofdstukken ieder in 2 Aviertjes had weten te pakken was hij wat mij betreft"een 'Meister' geweest. Nu is het voornamelijk gefilosofeer en offshow van wat hij allemaal kan citeren. De toekomst van de bibliotheek ben ik er niet tegengekomen.
**
* De draagbare lichtheid van het bestaan: het alledaagse gezicht van de informatiesamenleving / onder red. van Valerie Frissen en Jos de Mul. Kampen, Uitgeverij Klement, 2008. ISBN 9789086870301
Bundel essays, van een aantal, jonge, onderzoekers die berichten over de relatie technologie en samenleving. Uitgangspunt is dat dagelijkse, triviale en soms onvoorspelbare praktijken van de gebruikers de loop van de technologie en de vorm van de informatiesamenleving bepalen. Het gaat over de 'bricoleurs'i.t.t. íngenieurs', een antropologische benadering van triviale telefoongesprekken, ambient intelligence, de technologische toekomstvisie en de emancipatie van de gebruiker. Gadgets maken het leven misschien niet draaglijker, maar zeker wel draagbaarder, is de slotconclusie.
**
* De snavel van de vink: evolutie op heterdaad betrapt / door Jonathan Weiner. Contact, 1994. ISBN 90 25406157. Vert. van The beak of the finch: a story of evolution in our time.
Uitleg over het voortgaande proces van natuurlijke selectie. Met als voorbeeld de evolutionaire aanpassing van Darwin-vinken op de Galapagoseilanden, wordt helder uitgelegd wat evolutie is.
**
* Het nieuwe werken: op weg naar een productieve kenniseconomie / door Dik Bijl. Den Haag, Academic Service, 2007. ICT bibliotheek. ISBN 9789012119481
Het nieuwe werken, een door Microsoft in 2005 beschreven concept voor verhoging vasn de productiviteit van de individuele kenniswerker. Uitgaande van de factor 4 index met als hoofdcategorieen technologie, organisatie, cultuur en inspiratie wordt de werknemer persoonlijk aangesproken op zijn werkhouding. Werkplek aanpassing, flexplekken en werken kan overal, en werktijd aanpassing, geen 9-5, maar altijd en overal tussendoor. Boekje leest lekker weg.
**
* Iedereen : hoe digitale netwerken onze contacten, samenwerking en organsiaties veranderen. / door Clay Shirky. Business Contact, 2008 ISBN 9789047000808. Vert van 'Here comes everybody'
Gemakkelijk leesbaar boek over de sociaal-psychologische veranderingen, die mogelijk zijn geworden door toepassing van Internetapplicaties.
16 nov 2011
Gelezen in 2009/2010
Bijeenkomst 11 november van het Onderzoeksdataforum
Het Surfshare programma eindigt dit en zal worden afgesloten met de SURF Onderzoeksdag op 9 februari 2012 in Media Plaza in Utrecht.
“Met het SURFshare-programma wil SURFoundation een gemeenschappelijke infrastructuur realiseren die de toegankelijkheid èn de uitwisseling van onderzoeksinformatie bevordert.”
Maar het Onderzoeksdataforum blijft bestaan.
Deze bijeenkomst zal worden besteedt aan 2 nieuwe rapporten: het Witboek dataprofessionals en de rapportage Podium Plus.
Daarna zal Bram van de Werf dieper ingaan op metadata.
De werkgroep Datastewardship van het Onderzoeksdataforum (waar ik zelf deel van heb uitgemaakt) heeft een witboek geschreven over het beroep dataprofessional. De werkgroep doet verschillende aanbevelingen in het Witboek Dataprofessionals in Nederland. Rob Grim voorzitter van de werkgroep geeft een nadere toelichting op het Witboek en neemt de aanbevelingen door.
Het Witboek Dataprofessionals geeft een overzicht van de datamanagement-ondersteuning bij 3 onderzoeksinstellingen NIOO, TUD, UvT
Rob geeft in het kort zijn impressie over de drie organisaties:
NIOO: afspraken over workflow – kwaliteit van dataverzameling – koppeling publicaties
TUD: permanente toegankelijkheid – veel DIY – registratie ws output
UvT: ondersteuning domein experts – lokaal naar centraal – geen opslag cultuur
De werkgroep is in 2009 gestart met het opstellen van “terms of reference:: een afbakening tot het profiel/ de competenties van ondersteuners van onderzoekers
Er wordt ingegaan op de rol van de dataprofessional in drie fasen van onderzoek: voorbereiding, uitvoering, evaluatie.
De aanpak is een literatuuronderzoek, gevolgd door een case studie bij ieder van de drie deelnemende instellingen d.m.v. interviews met onderzoekers, om te kunnen beschrijven wat de algemene knelpunten zijn en wat voor ondersteuning zij nodig hebben.
Datamanagement onderscheiden we in drie groepen: data-archivering, metadata, digitale duurzaamheid.
Uit literatuur komen vier belangrijke vaardigheden voor dataprofessional naar voren: data-archivering, softskills, kennis van wetenschappelijk onderzoek(smethoden), ict-skills.
- Rob verwijst hier ook naar de presentatie van Youngseek Kim tijdens de 6th International Data Curation Day over ‘Education for eScience professionals”.
Overigens ook aardig om te lezen is de masterscriptie De Datalibrarian in Nederland van J. Puttenstein, die in algemene zin schets hoe de situatie bij de Nederlandse Universiteiten is.-
Wat zijn de aanbevelingen:
Er moet training en opleiding worden aangeboden, niet alleen voor ondersteuners, maar ook voor onderzoekers zelf, specifiek maar ook een algemene basis voor alle wetenschappen.
Verder kan gekeken worden naar: UFO-profielen, GO-opleidingen, op maat trainingen, docenten, bijv. in overleg met eScience center.
Vervolgens kwam Paulien Wiersma over project PodiumPlus mogelijkheden tot data-opslag mbv Dataverse
Ervaringen met open source programma Dataverse (Harvard) en ervaringen met samenwerking met andere universiteiten. Er is nu een officiële dienst van Universiteit Utrecht, hosting bij Vancis (Sara dochter), en is nu een openbaar netwerk.
De metadata wordt geharvest door Harvard DataVerse: met federatieve inlog. Het is bedoeld voor middellange termijn opslag met koppeling naar DANS via SWORD protocol.
In het project heeft Paulien de licentievoorwaarden Dataverse vergeleken met DANS en 3TUD, en ook een vergelijking van de metadata en formaten.
Bijvoorbeeld nu vanwege de NWO-verplichting om data op te slaan daardoor komen er toch meer mensen naar DVN. Zie het als voorportaal., lokale variant van Harvard DataVerse
Grote machine gegenereerde data past er niet in, maar het werkt snel: onderzoekers krijgen meteen een URL – persistente handle.
Na de thee geeft Bram van de Werf een presentatie over ‘Metadata en sustainability”. Bram is directeur van Open Planets Foundation over metadata en duurzaamheid bij lange termijn opslag van onderzoeksgegevens. Voorheen bemoeide hij zich met Europeana. Europeana heeft ook een Toughtlab waarin ze een aantal tools voor het verrijken van metadata tonen Europeana is oorspronkelijk ook bedoeld als metadata-project.
Ipv preservation praten over lange termijn toegang.
Er is te snel overgestapt op het omzetten – normaliseren – van data- bits. Daar is niet genoeg over nagedacht, aldus Bram. Metadataschema’s zijn niet zo belangrijk als er maar over nagedacht is en het kan interopereren met anderen. Hoe beter de metadata hoe beter de objecten gebruik gaan worden”.
Met de community onderzoeken van de technische metadata, niet bij ingest (want dan creëer je een bottleneck), maar maak een enrichment layer in je repository en gebruik/ontwikkel tools om de metadata daar te verrijken. vd Werf ziet veel in het verrijken van de metadata door in de repository de hiaten in de technische metadata op te sporen
Gebruik is de sleutel, kijk naar de requirements en use cases, die gebruikt kunnen worden voor data mining en data modelling
Het Planets project, waaruit de Open Planets Foundation voorkomt had als ambitie het opzetten comptetentiecentrum waaruit de lidstaten dan kunnen putten (voor diensten en expertise).
Tijdens de discussie aan het slot van de middag bleek de centrale vraag “ Wat is noodzakelijk om de data te hergebruiken”.
Vaak is het heel moeilijk om data geschikt te maken voor meerdere functies bijv.voor omzetten in Narcis en KB etc. Beginnen met Basale ontsluiting en daarna discipline specifieke metadata toevoegen.
20 okt 2011
Het Bureau

Dit najaar ben ik begonnen te lezen in Het Bureau van J.J.Voskuil. Een romancyclus in 7 delen die de dagelijkse gang van zaken verhaalt vanaf de jaren '50 tot '90 op het KNAW-instituut voor Volkskunde (het huidige Meertens-instituut).
Hoofdpersoon is Maarten Koning, die eerst als assistent, later opvolger van A. Beerta afdelingshoofd Volkskunde is.
Sinds 2007 ben ik zelf werkzaam bij KNAW, en ik kan zeggen dat ik het beschreven, de sfeer en de relaties zeer herkenbaar vind.
Het Meertens-instituut zelf ken ik niet zo, maar de omschreven sfeer en het gedachtengoed leeft nog steeds in KNAW-kringen. Prachtig beschreven zijn de soms moeizame contacten met de collega's (sociale omgang was niet Maarten Koning's sterke kant) en zijn overdenkingen, aarzelingen en twijfels.
Het Meertens-instituut heeft wat oude foto's over de tijd waarin Het Bureau speelde op het web gezet en er zijn wat naamsverwijzingen (niet bijgewerkt) gepubliceerd. Interessant is ook het artikel van J. Goossens over het wetenschappelijk bedrijf uit de roman " J. Goossens, ‘Het wetenschappelijk bedrijf in Voskuils roman Het Bureau.’ In: Literatuur 14 (1997), p. 130-137. ".
Fascinerend om te lezen.
Het eerste deel werd gepubliceerd en er was een tijdlang sprake van een literaire hype rondom de cyclus. Nu is er enkel nog een twitter. Maar samen met een collega beleef ik er veel plezier aan.
3 okt 2011
CWTS-cursus meten van wetenschappelijke output 5

Vorige week ben ik 5 dagen lang naar Leiden getogen voor deGraduate Course “Measuring Science and Research Performance” van het CWTS, hetCentre for Science and Technology Studies van de Unviersiteit leiden.
- World of Science, Technology and Innovation
- Research Performance Measurements and Indicators
- Research management perspectives
- Science Mapping
- Science Policy Contexts
- Scientometrics 2.0
Uiteraard is het zorgvuldig interpreteren, verzamelen en schonen van gegevens belangrijk en uiteraard dienen die cijfers in een geheel met andere indicatoren(ook kwalitatieve) gebruikt te worden. Maar soms geven die quick-and-dirty ggevens toch wel een aardig trend aan.
Zelf worstel ik altijd met de onderwerps-indelingen en dat blijkt ook inderdaad een groot probleem te zijn. Om nog maar te zwijgen van de gemankeerde aandachtvoor humaniora in de cijfergegevens. Wellicht dat het met de komst van de BookCitation Index van WoS beter gaat.
Erg interessant vond ik ook de ingangen tot het waarderen van wetenschappelijke onderzoek in termen van economische groei, innovatie en maatschappelijke waardering.



 Als cursusmateriaal kregen we het boek ‘Citation analysis in research evaluation’van Henk Moed, en dat ga ik komende week eens doorlezen, venals ‘The Publish or Perish Book’ van Anne-Will Harzing (hoorde niet tot eesmateriaal).
Als cursusmateriaal kregen we het boek ‘Citation analysis in research evaluation’van Henk Moed, en dat ga ik komende week eens doorlezen, venals ‘The Publish or Perish Book’ van Anne-Will Harzing (hoorde niet tot eesmateriaal).CWTS-cursus meten van wetenschappelijke output 4
Hoe kun je het wetenschappelijk onderzoek meten en de prestaties van universiteiten met elkaar vergelijken?
[In de ranking-systemen worden alleen universiteiten met elkaar vergeleken, omdat er voor onderzoeksinstituten - zoals bijv. het excellent presterende Max Planck Inst. geen vergelijkbare plek is, ook niet voor afzonderlijke onderzoeksinstituten. ook noemt Van Raan het probleem van de academische ziekenhuizen, die vaak verantwoordelijk zijn voor de helft van de output, maar soms moeilijkaan een universiteit te koppelen].
Allen zijn gebaseerd op de 2 commerciële producten (WoS)en (Scopus).
1. TimesHigher Education is ingedeeld in 5 categorien (teaching, research, citations, industry income, international) met een verschillende weging gebaseerd op ‘expert enthusiasm’. 2/3 is gebaseerd op citaties.
2. QS deelt ongeveer in dezelfde categorieen in, maar heeft als extra ‘employer reputation’
3. Shanghai, Academic Ranking of World Universities(ARWU), is heel erg ‘size dependent’. Trotsop oude prijswinnaars, maar zegt niets over potentieel. Bij citaties wordt alleen gekeken naar de highly cited (dus past performance)met nadruk op reputatie.
4. Leidenranking .Het kost veel tijd om websites na te kijken en om netwerk met contactpersonente onderhouden. Ranking op basis van genormaliseerde bibliometrische indicatoren, nu MNCS2 (voorheen CPP/FCSm). Het algemeen plaatje is dat als je als universiteit bij eerste 300 hoort het nog goed zit, daarna gaat de curve scherp naar beneden (hypothese van Raan: er zijn niet meer goede wetenschappers om meer goede universiteiten te bevolken). Voor Frans en Duits zijn aparte lijsten gemaakt.Gemiddelden in studies zijn niet altijd de beste indicator vanwege de ‘skewed distribution’, dan is highly cited beter (A/EPtop10%)
5. U-Multirank, een EU-project.
Naast dit soort ranking kunje ook op andere terreinen aan internationale benchmarking doen. Maar het is lastig om vergelijkbare indicatoren op te stellen.Tijssen geeft een overzicht van de wetenschappelijke indicatoren; technologie-indicatoren (zie ook het University-industry Scoreboard van CWTS); en innovatie indicatoren (bijv. voor het EriC,Evaluation of Research in Context van de KNAW en VSNU is geprobeerd te valoriseren, maar verder dan showcases komt men (nog) niet.
Ook Leru heeft alleen case-beschrijvingen).
Science mapping
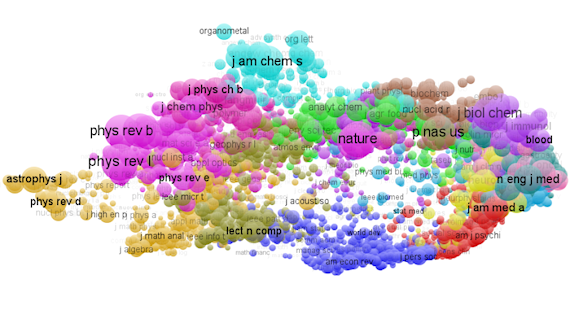
Naast het ranken wordt er m.b.v. allerlei moderne textmining instrumenten geprobeerd de hele wetenschap in kaart te brengen. Kaarten die gebaseerd zijn op de bibliometrische netwerken van publicaties, co-auteurschap, cocitaties e.d.CWTS heeft voor visualisering van die gegevens de zogenoemde VosViewer ontwikkeld. Door de kaarten kun je aldus Noyons en Waltman, dichter bij de data blijven. De kaarten maken clustering mogelijk en kunnen verschillende dimensies weergeven. Van de basis bibliometrische netwerken, maak je afgeleide netwerken die je naar symmetrische matrixen kunt overbrengen en die kun je visualiseren.Zo heeft CWTS bijvoorbeeld alle onderwerpsgebieden uit WoS voor indelen van tijdschriften in kaart gebracht.Dat geeft toch een mooi beeld van de wetenschap en de vertegenwoordiging van artikelen in de WoS-database. [Ik kan me herinneren dat we vroeger zoiets geprobeerd hebben m.b.v. thesauri, maar dat is toen gestrand, ook vw de omvang]. Ook een mooie is de kaart van de tijdschriften zelf:
Cornelis van Bochove neemt een heel andere invalshoek, hij kijkt naar de invloed van Human Resources Management en carrière-politiek op de wetenschappelijke prestaties.Stelling ”Scienceoutput is the sum of competence, aptitude and randomness”. Hij wil onderzoeken of het voor de prestaties wat uitmaakt als je een onderzoeker eerder een vaste aanstelling geeft, dus eerder in zijn carrière uitselecteert. Hij laat met een Pareto-distributie zie hoe dat in de verschillende scenario’s eruit ziet. Als verschillen tussen mensen groter zijn, dan is de invloed van selectie op totale output enorm. Snelle selectie levert dus meer op.Van Bochove kijkt ook naar de economische groei, wat is het aandeel van de wetenschap in de economische groei. Daarbij komt hij tot nogal wat verrassende uitspraken. Fundamenteel onderzoek is nodig om de barriere van de ‘known laws of nature’ te verleggen. Fundamenteel onderzoek vraagt om extra getalenteerde mensen, waarbij de tijdsfactor (=leerfactor) belangrijker is dan geld; meer Einsteins, of rijkere Einsteins hadden niet sneller de relativiteitstheorie kunnen ontdekken. Je krijgt snelle groei als je veel geld stopt in toegepaste R&D op basis van bekende ‘laws of nature’ (zie Azie)Je krijgt stabiele groei op basis van het basic research model afhankelijk van leertijd (zie Japan, vanaf 80 jaren hadden ze niveau van het Westen gehaald en basic research genegeerd toen ging het neerwaarts).De essentie van economische groei zit hem dus, aldus Van Bochove in het Basic Research Model.Die boodschap, om met name te investeren in fundamenteel onderzoek is een interesante gedachte en zal hij uitwerken in een nog te verschijnen artikel.
2 okt 2011
CWTS-cursus meten van wetenschappelijke output 3
Databases en indicatoren.
CWTS zelf maakt gebruikt van de literatuurdatabase van Thomson Reuters (Web of Knowledge) die zij zelf offline ontvangen en bewerken. Uiteraard doen zij ook onderzoek naar de bruikbaarheid van andere databases en in ieder geval is het, aldus van Raan een zegen dat er meer concurrentie (Scopus, Google Scholar) is en dus het monopolie van Web of Science afkalft.
Google Scholar is vrnl. onbruikbaar, omdat er geen gegevens bekend zijn over de dekking daarvan, maar een collega op de ISSI conferentie in Zuid Afrika, zei wel, aldus een van onze docenten, dat hij blij was dat er in ieder geval iets is voor m.n. de humaniora. [Web of Science is erg gefocussed op life sciences en heeft in andere wetenschapsgebieden niet of zeer onvolledige dekking).Scopus wordt steeds beter en steeds completer, hoewel er nog steeds onverklaarbare ‘gaps’ zitten.
impact factor
Uiteraard ken ik de JCR: Journal Citation Report, waarbij Thomson Reuter ieder jaar de impact factoren van de tijdschriften publiceert. Scopus heeft daar een alternatief voor de SNIP. De SNIP index vergelijkt de citaties die een tijdschrift krijgt met de citaties die het (in de referenties bij de artikelen) geeft. En daarmee, aldus van Leeuwen krijg je een normalisatie voor het veld en worden de cijfers beter vergelijkbaar.
CWTS heeft zelf een nog betere indicator ontwikkeld de JFIS (=MNJS), die dus de citaties in een tijdschrift voor het veld normaliseert (afzet tegen het gemiddelde van die onderwerpsgroep) en die bovendien niet alleen naar de citaties uit een bepaald jaar kijkt, maar ook die van voorgaande jaren.Maar omdat ze WoS materiaal gebruiken mag de JFIS niet openbaar.
Dat neemt niet weg dat een gemiddelde zoals de journal impact factor-SNIP-JFIS toch niet zulke goede indicatoren zijn, omdat je bij alle ziet dat de distributie van de citaties ongelijk verdeeld is over de tijdschriftartikelen: een klein deel van de publicaties krijgt het merendeel van de citaties.
Wat indicatoren betreft gebruikt het CWTS het liefst de ‘genormaliseerde’indicatoren, omdat die beter met elkaar vergelijkbaar zijn, omdat omvang en veld waarin gepubliceerd wordt daarmee worden gelijkgeschakeld.
Niet/genormaliseerde indicatoren :
P= number of publications (alleen substantiele bijdrage: article, review, letter)
TCS= total citation score (self citations ignored)
MCS= mean citation score (gemiddelde citatiescore)
Genormaliseerde indicatoren:
MNCS = C/FCS + + de citatiescore gerdeeld door de veldscore = gemiddelde score in een onderwerpsveld
MNJS=JCS/FCS + + en dat kun je ook uitrekenen voor een tijdshcrift alss geheel (JFIS)
Pptop10%= om de zogenoemde ‘outliers’(enkele publicatie die extreem veel geciteerd wordt) er uit te halen en te kijken hoe de prestatie is in het topsegment van het onderzoeksgebied.
Van belang bij het bepalen van een vergelijkbare citatiescore is het citatievenster. Eventueel kun je aan een bepaald documenttype een bepaald gewicht toekennen (bijv een ‘letter’ telt dan minder zwaar als een volledig artikel).
Ludo Waltman, die de indicatoren presenteert gaat ook nog in op de h-index met de woorden ‘gebruik nooit de h-index’, iets waarover hij ook zal publiceren in JASIST.
Wat is er mis met de h-index?
De h-index geeft het kruispunt aan van aantal publicaties en aantal citaties per publicatie van een onderzoeker. Volgens CWTS-berekeningen is dat een inconsistente indicator, hij toont nl bij gelijkblijvend gedrag niet een gelijkmatige verhoging van de index. De h-index kan nooit omlaag gaan en ook nooit hoger worden dan aantal publicaties. Ook normaliseert hij niet naar verschillen in het veld, naar leeftijd en lengte van de wetenschappelijke carriere van de onderzoeker, en naar zijn gekozen publicatiestrategie.
Kortom het deugt niet.
[ Jammer genoeg is het wel een erg handig getal, wat tamelijk makkelijk zelf te produceren is zonder ingewikkelde berekeningen en toegang tot moeizaam verkregen gegevens. En zolang daarvoor i de plaats geen net zo handig hanteerbaar instrument voorhanden is zal dat ook wel gebruikt blijven, denk ik.]
Het alternatief wordt tijdens de cursus ook aangereikt: dat is wat de CWTS al doet door in samenwerking met onderzoekers en tegen de achtergrond van het onderwerpsgebied, genormaliseerde gschoonde citatiegegevens te gebruiken samen met kwalitatieve peer evaluatie.Grootse problemen bij alle indicatoren zijn er doordat onderwerpsclassificeringen niet helder zijn en er een betere methode zou moeten worden gevonden voor het contextualiseren van het onderwerpsgebied waarin onderzoeker/onderzoeksgroep werkzaam is.
Robert Tijssen gaat nog in op het begrip 'excellence'.In de huidige praktijk worden universiteiten, onderzoeksgroepen en -instituten iedere zes jaar ge-evalueerd volgens het SEP (Standaard Evaluatie Protocol). Het SEP geeft ook de definities voor de classificaties "excellent", "very good", "good" etc. Hoewel collega van Leeuwen eerder zei "er is geen directe link tussen citaties en kwaliteit, het moet altijd via 'impact'lopen " loopt het meten van kwaliteit toch vaak over het meten van impact. CWTS beveelt wel aan de gehele portfolio van kwalitatieve peer review en kwantitatieve scientormetrische gegevens te hanteren. Toch geeft een 'highly citated' analyse wel een indicatie van goede kwaliteit.Aardig is het onderzoek naar bibliometrische gegevens van Spinozaprijswinnaars. "De NWO-Spinozapremie is de hoogste Nederlandse onderscheiding in de wetenschap". Als je de resultaten van de Spinozaprijswinnaaars-kandidaten met de indicator MNSC kalibreert kom je gemiddeld op 2.1 (2x het wereldgemiddelde), kijk je alleen naar de winnaars dan kom je uit op 3 (met een standaard deviatie van 1.7 - meestal humanoria). Dat geeft toch aan dat je met die indicator, mits gekalibreert naar veld wel iets kunt zeggen.Ook blijkt dat Thomson Reuters er in zijn voorspellingen naar de Nobelprijswinnaars redelijk vaak raak schiet.Voor profilering van een onderzoeksgroep is het wel noodzaak de uitschieters eruit te halen, dat is geen voorbeeld van excellence. Dat kun je doen met de A/EPtop10% of zelfs A/EPtop1% scores.
1 okt 2011
CWTS-cursus meten van wetenschappelijke output 2
Maatschappelijke relevantie en de waarde van de wetenschap voor innovatie.
Prof Robert Tijssen gaat in op kenmerken van wetenschap en innovatie, hoe kun je wetenschap, de bijdrage van de wetenschap aan innovatie i.c. innovatieve producten herkennen?
De outputs zijn niet alleen publicaties, maar ook standaarden, training van Phd’s, patenten e.d., die hebben impact op de media en overhead en dat leidt tot beleid en economische inpassing in nieuwe processen en producten. Daaruit vloeien dan weer de ‘outcomes’ voort, de maatschappelijke en commerciële opbrengsten.
Om die opbrengsten en invloeden te meten kun je verschillende toolboxen gebruiken waaronder bibliometrische studies )maar ook econometrische en management studies en surveys.
Het is nog niet zo eenvoudig om de invloed van wetenschappelijk werk te meten, omdat je eerst moet weten wie de gebruikers zijn en wie er van profiteren, omdat er vaak sprake is van meervoudige invloeden. Ook kan er soms een behoorlijke tijdspanne zitten tussen onderzoek en een meetbaar resultaat. Causaliteit blijft moeilijk aantoonbaar.
Anders dan bijv. bibliometrische citatiepatronen laten ook surveys een overzicht zien van de waarde van de wetenschap. Bijvoorbeeld in een survey heeft de EU laten onderzoeken wat de houding van Europeanen is t.a.v. de wetenschap (Eurobarometer 340). Daaruit blijkt dat toch meer dan de helft van de bevolking positief staat t.o.v.de wetenschap en de maatschappelijke bijdrage van de wetenschap. Later in de week laat Ingeborg Meijer ons zien dat er naast bibliometrische methoden en survey’s nog andere methoden zijn om het maatschappelijk belang van onderzoek te meten. Zij hebben dat gedaan bij LUMC. Dat is wel een aardige aanvulling i.v.m. toenemend belang van ‘valorisatie’ (maatschappelijke waarde, ook ondernemerschap of publiek-private samenwerking).
Wel kom je, aldus Meijer snel in discussie terecht over meten van wetenschappelijke resultaten: kwantitatief vs kwalitatief, strikt wetenschappelijk en/of valorisatie, welke indicatoren je gebruikt en hoe die ingezet (c.q. gemanipuleerd )kunnen worden.
De methodologische vragen naar de robuustheid van de systematiek en de waarde ervan, m.n. vanwege het ontbreken van de relatie tot de wetenschappelijke kwaliteit.
Toevalligerwijs is er net die dag een onderzoek gepubliceerd van een consultancy bureau dat de economische verdiencapaciteit van de universiteit Leiden heeft gemeten en tot de conclusie komt dat leiden 4x zoveel opbrengt als het kost.
Tijssen laat in een aardige grafiek uit Google labs zien dat je bijvoorbeeld met Google books een aantal onderwerpen kunt vergelijken door in de full text van boeken te zoeken en te kijken naar het voorkomen van het gebruik van die termen (termen als innovatie, bibliometrics).